一致性哈希
常用场景
常用于负载均衡,数据分片等场景。
原理
与最简单的负载均衡算法类似,一致性哈希也是基于取模运算。
主要结构是一个哈希环,上面有 2^32 个槽位,从 0 到 2^32-1,顺时针旋转,0 与 2^32-1处汇合。如果用服务器节点作为槽位,那么可以用 IP 地址作为标志,hash(NODE_IP) % 2^32 的结果可以作为节点所处的槽位。
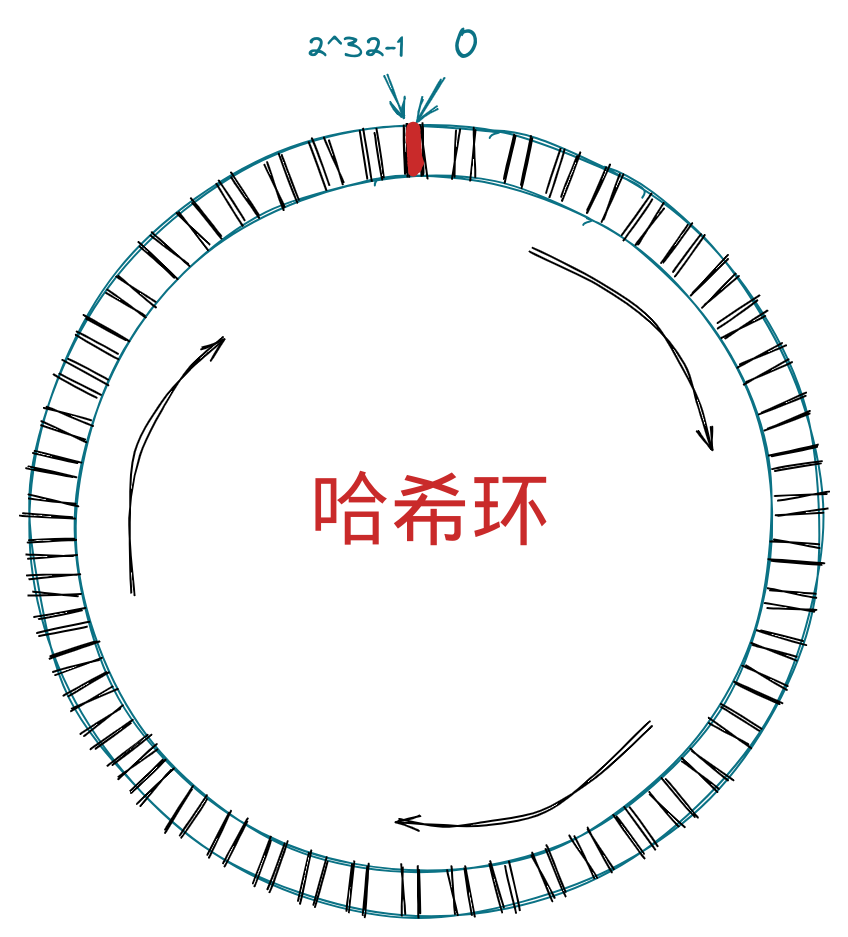
当有多个节点加入到哈希环中,看起来会像是这样。
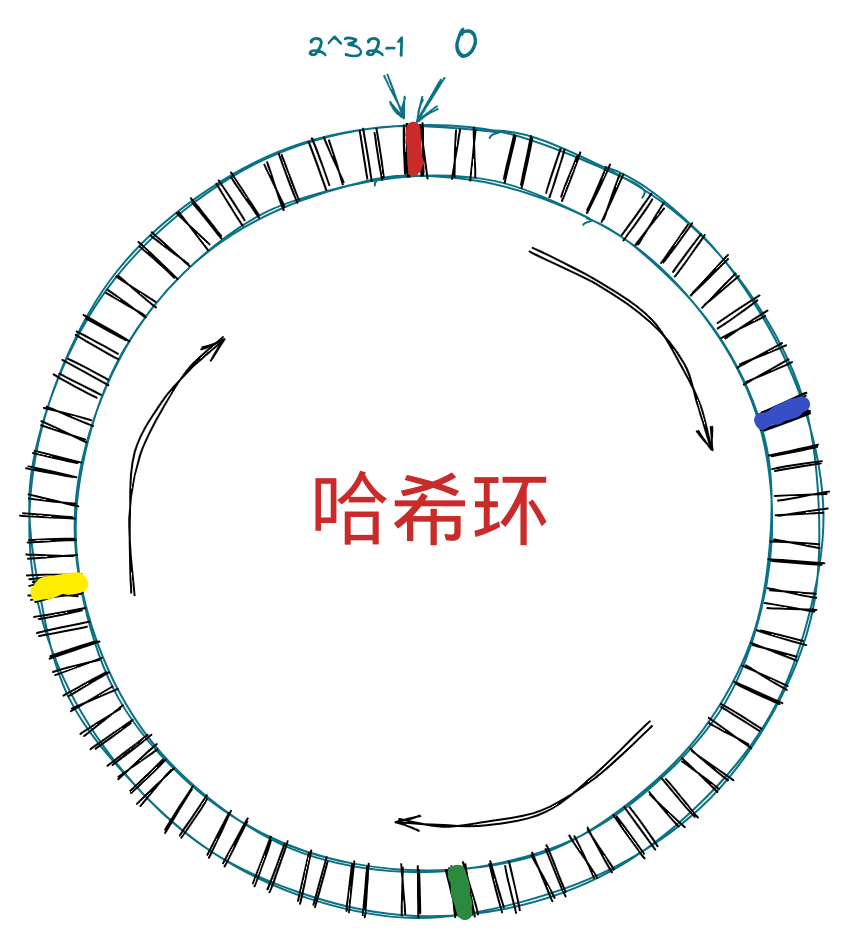
节点会分布在哈希环的各处,这里我们可以将那些被一致性哈希算法分配(可以看作被负载均衡器分配的任务)的东西称作任务,将任务的特征对2^32取模,我们可以得到一个槽位,这个操作可以看成 hash(任务) % 2^32 。接下来任务当然需要被工作节点接收,寻找工作节点的方式就是从通过对任务进行hash后取模得到的槽位开始,顺时针遇到的第一个节点会得到这个任务。
与简单取模的区别
简单取模无法应对工作节点会扩容或者缩容的场景,比如在一个分布式缓存系统中,有 5 个节点,每个缓存节点都存储了大量缓存,我们通过一个 key 找到对应的 value 的方式一般就是对 key 做一次 hash 后再对 5 取模,得到存储这个 key 的节点,并从该节点中得到相应的 value。
如果我们需要增加或减少一个节点,比如节点增加到了6个,那么每个 key 的 hash 都需要对 6 取模,得到的结果(也就是存储着相应 K-V 的节点)会发生变化,也就是无法通过原来的 key 找到原来存储着这对 K-V 的节点了,那么就必须调整大量节点的缓存分布。也就意味着这时大量的缓存会失效,在分布式场景中极易造成雪崩。
而在一致性哈希中,如果新增或减少一个节点,相应的操作就是在哈希环上的某个槽位插入或删除一个节点,就只需要调整对应槽位相邻节点的缓存分布。无非就是在删除一个节点时,将这个节点中存储的 K-V 转移到顺时针下一个节点中;在增加一个节点的时候,在新增节点顺时针第一个节点中,寻找落在新增节点的逆时针方向的 K-V 直到遇到逆时针方向的下一个节点,并将它们调整到新节点中。
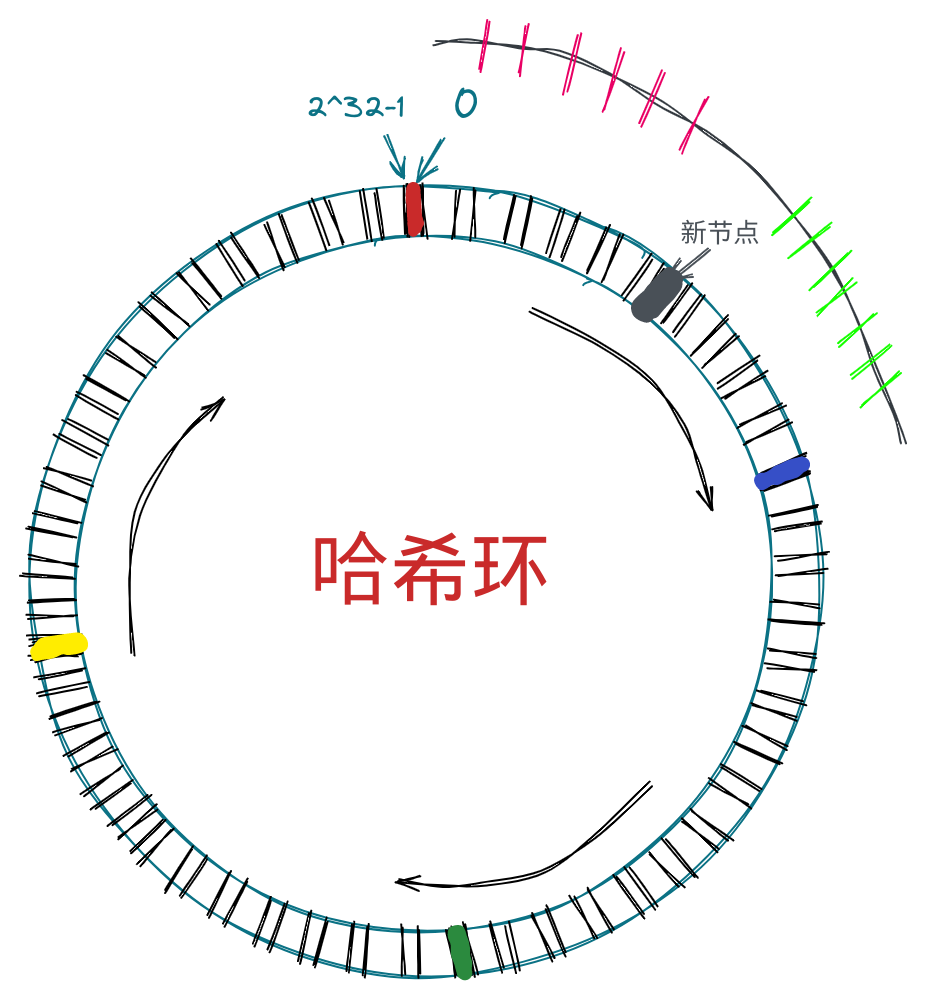
就像图中所示,在新增节点时红色部分会被调整到新节点中,绿色部分保留在原本的节点中。
在有大量节点的分布式环境中,这样调整的代价就会小很多。
虚拟节点
在上面的内容中,很容易发现一个新的问题,那就是当节点的数量并不多的时候,很容易存在任务分配不均的情况,可能大量的任务落到的槽位会集中在某块区域,而其它区域的槽位则没有那么多的任务,当一个节点不堪重负被压垮后,那么压力会顺延给顺时针的下一个节点,形成雪崩。这时候就需要引入虚拟节点了。
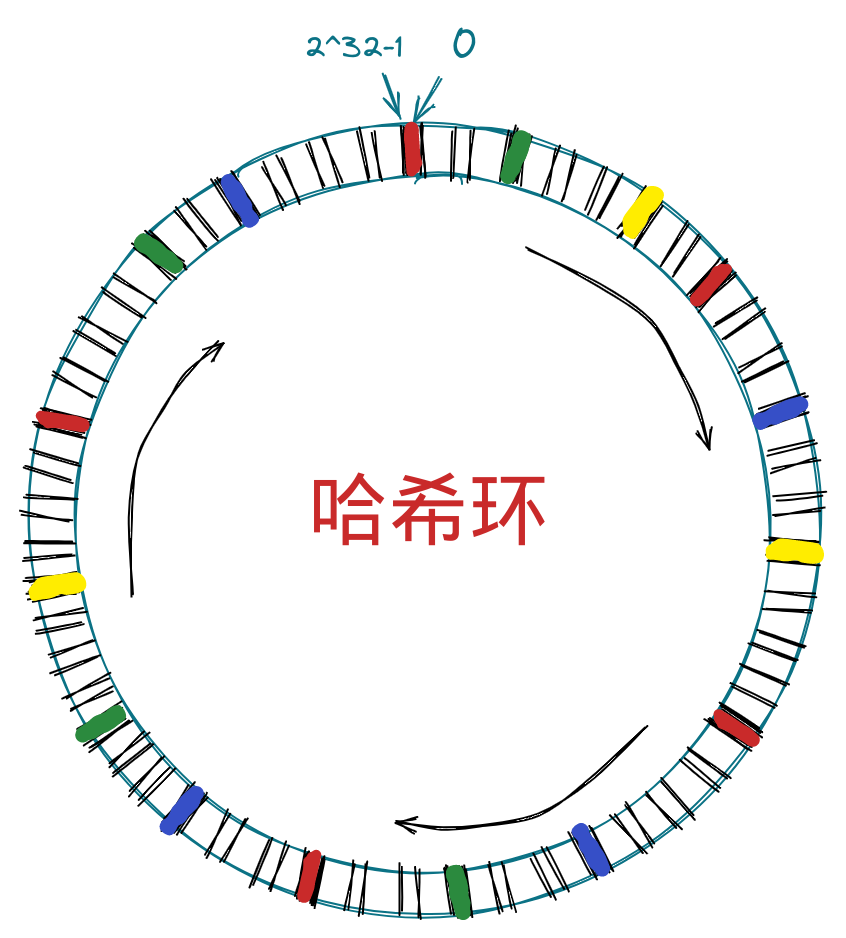
比如对节点多次 hash 并取模(或者其它方式,比如对第一次 hash +1 并取模得到第二个槽位),得到若干个槽位,这些槽位均代表该节点,那么就可以大大减轻任务分布不均的问题了。
实现
GO 语言
我给出了较详细的注释,直接贴出我的实现:
consistent_hash.go
package consistenthash
import (
"fmt"
"sort"
"sync"
)
type PlaceHolder struct{}
// HashFunc 定义了一个哈希函数.
type HashFunc func(data []byte) uint64
type ConsistentHash struct {
lock sync.RWMutex
// 虚拟节点数
virtualNodeNum uint64
// 哈希环
ring map[uint64]string
// 节点和它对应的虚拟节点
nodes map[string][]uint64
// 记录当前 ring 上的所有虚拟节点.
// 因为 map 不可排序,我们又需要让所有的 hash 值有序
keys []uint64
// 需要使用的哈希函数
hashFn HashFunc
}
// DefaultVirtualNodeNumber 默认虚拟节点数量,不能小于默认数量
var DefaultVirtualNodeNumber uint64 = 100
// NewConsistentHash 创建一个一致性哈希
func NewConsistentHash() *ConsistentHash {
// 目前只使用 xxhash
return NewCustomConsistentHash(DefaultVirtualNodeNumber, xxhashSum64)
}
func NewCustomConsistentHash(num uint64, hash HashFunc) *ConsistentHash {
if num < DefaultVirtualNodeNumber {
num = DefaultVirtualNodeNumber
}
if hash == nil {
hash = xxhashSum64
}
return &ConsistentHash{
virtualNodeNum: num,
ring: make(map[uint64]string),
nodes: make(map[string][]uint64),
hashFn: hash,
}
}
// Add 添加节点
func (ch *ConsistentHash) Add(node any) {
ch.AddWithVirtualNodes(node, ch.virtualNodeNum)
}
// AddWithVirtualNodes 添加节点的同时添加虚拟节点
func (ch *ConsistentHash) AddWithVirtualNodes(node any, virtualNodeNum uint64) {
// 如果节点已经存在, 则先移除节点
ch.Remove(node)
if virtualNodeNum > ch.virtualNodeNum {
virtualNodeNum = ch.virtualNodeNum
}
// 将 node 转换为字符串
nodeStr := Repr(node)
ch.lock.Lock()
defer ch.lock.Unlock()
for i := uint64(0); i < virtualNodeNum; i++ {
// 生成虚拟节点的哈希值
hash := ch.hashFn([]byte(fmt.Sprintf("%s#%d", nodeStr, i)))
// 将虚拟节点添加到哈希环上
ch.ring[hash] = nodeStr
// 因为 map 不可排序, 所以需要记录所有的虚拟节点
ch.keys = append(ch.keys, hash)
// 在 nodes 中记录节点和它的虚拟节点, 用于移除节点
// (通过牺牲空间换取时间,这样就不用在移除节点的时候计算虚拟节点的哈希值)
ch.nodes[nodeStr] = append(ch.nodes[nodeStr], hash)
}
// 从小到大整理 keys
sort.Slice(ch.keys, func(i, j int) bool {
return ch.keys[i] < ch.keys[j]
})
}
// Remove 移除节点
func (ch *ConsistentHash) Remove(node any) {
ch.RemoveWithVirtualNodes(node)
}
// RemoveWithVirtualNodes 移除节点的同时移除虚拟节点
func (ch *ConsistentHash) RemoveWithVirtualNodes(node any) {
// 将 node 转换为字符串
nodeStr := Repr(node)
// 如果节点不存在, 则直接返回
if _, ok := ch.nodes[nodeStr]; !ok {
return
}
ch.lock.Lock()
defer ch.lock.Unlock()
delete(ch.nodes, nodeStr)
for i := 0; i < len(ch.nodes); i++ {
// 将虚拟节点从哈希环上移除
delete(ch.ring, ch.nodes[nodeStr][i])
// 从 keys 中移除虚拟节点
index := sort.Search(len(ch.keys), func(i int) bool {
return ch.keys[i] == ch.nodes[nodeStr][i]
})
if index < len(ch.keys) && ch.keys[index] == ch.nodes[nodeStr][i] {
ch.keys = append(ch.keys[:index], ch.keys[index+1:]...)
}
}
}
// Get 获取 key 对应的节点
//
// 如果哈希环为空, 则返回 "" 和 false
func (ch *ConsistentHash) Get(key any) (string, bool) {
ch.lock.RLock()
defer ch.lock.RUnlock()
// 将 key 转换为字符串
keyStr := Repr(key)
// 计算 key 的哈希值
hash := ch.hashFn([]byte(keyStr))
// 在哈希环上查找节点
return ch.search(hash)
}
// search 在哈希环上查找节点
func (ch *ConsistentHash) search(hash uint64) (string, bool) {
// 如果哈希环为空, 则返回空字符串
if len(ch.ring) == 0 {
return "", false
}
// 如果 hash 在 ring 上直接命中,则直接返回对应 node
if node, ok := ch.ring[hash]; ok {
return node, true
}
// 如果未命中, 则找到第一个比它大的哈希值
// 因为 hash 可能会比 ring 上的所有哈希值都大,这时我们希望从头开始算,所以需要取模
index := sort.Search(len(ch.keys), func(i int) bool {
return ch.keys[i] > hash
}) % len(ch.keys)
node := ch.ring[ch.keys[index]]
return node, true
}
hash.go
//nolint:unused
package consistenthash
import (
"github.com/cespare/xxhash"
"github.com/spaolacci/murmur3"
)
func murmur3Sum64(data []byte) uint64 {
return murmur3.Sum64(data)
}
func xxhashSum64(data []byte) uint64 {
return xxhash.Sum64(data)
}
repr.go
package consistenthash
import (
"fmt"
"reflect"
"strconv"
)
// Repr 将节点转换为字符串
func Repr(v any) string {
if v == nil {
return ""
}
// 如果是 func (v *Type) String() string,我们不能使用 Elem()
switch vt := v.(type) {
case fmt.Stringer:
return vt.String()
}
val := reflect.ValueOf(v)
// 如果是指针类型,且不是nil,则取指针指向的值,如果指针指向的值是还是指针,则继续取指针指向的值
for val.Kind() == reflect.Ptr && !val.IsNil() {
val = val.Elem()
}
return reprOfValue(val)
}
func reprOfValue(val reflect.Value) string {
switch vt := val.Interface().(type) {
case bool:
return strconv.FormatBool(vt)
case error:
return vt.Error()
case float32:
return strconv.FormatFloat(float64(vt), 'f', -1, 32)
case float64:
return strconv.FormatFloat(vt, 'f', -1, 64)
case fmt.Stringer:
return vt.String()
case int:
return strconv.Itoa(vt)
case int8:
return strconv.Itoa(int(vt))
case int16:
return strconv.Itoa(int(vt))
case int32:
return strconv.Itoa(int(vt))
case int64:
return strconv.FormatInt(vt, 10)
case string:
return vt
case uint:
return strconv.FormatUint(uint64(vt), 10)
case uint8:
return strconv.FormatUint(uint64(vt), 10)
case uint16:
return strconv.FormatUint(uint64(vt), 10)
case uint32:
return strconv.FormatUint(uint64(vt), 10)
case uint64:
return strconv.FormatUint(vt, 10)
case []byte:
return string(vt)
default:
return fmt.Sprint(val.Interface())
}
}